Testeando una integración con S3
Publicado por Rubén Díaz el 28/10/2020
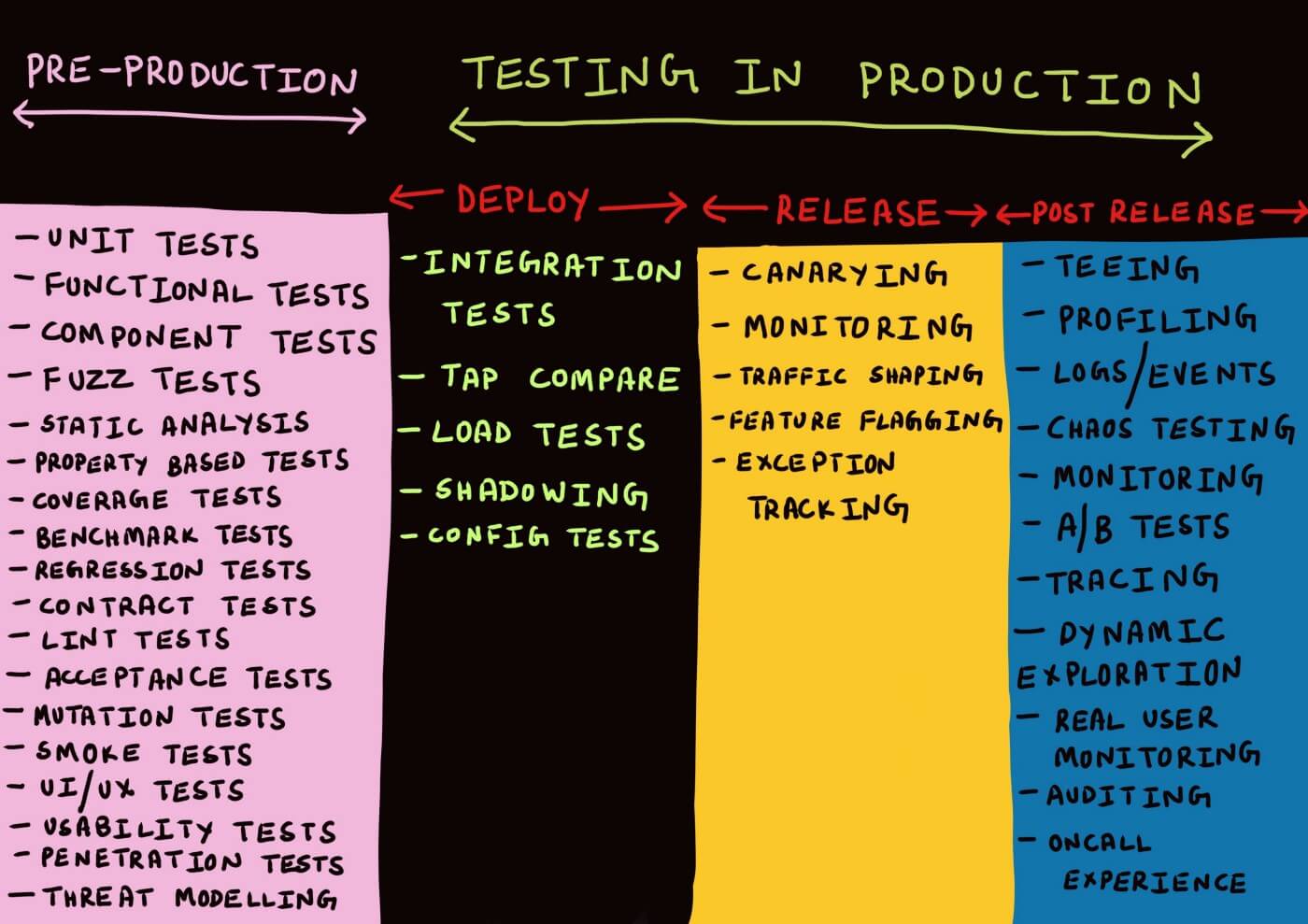
En uno de nuestros clientes actuales estamos ayudando en el desarrollo de un nuevo sistema que utiliza servicios de Amazon Web Services. Nos gustaría contarles el enfoque de testing que hemos seguido al integrarnos con S3, combinando tests locales contra imágenes Docker con tests en producción que se ejecutan periódicamente. Algunos de los tests que hemos hecho o el enfoque que hemos seguido lo hemos basado en los artículos de Cindy Sridharan sobre testing de microservicios y testing en producción.
Nuestra primera feature con S3
Una de las primeras features que hemos tenido que desarrollar ha sido la subida de imágenes, como por ejemplo para el perfil de usuario. Decidimos utilizar S3 (Simple Storage Service) para almacenar las imágenes que suben los usuarios. Por lo tanto, necesitamos integrarnos con S3 y una base de datos, para almacenar la información de usuario con la ruta a la imagen.
Hacer los tests contra la base de datos suele ser bastante sencillo. Utilizamos una imagen de Docker oficial que simula la base de datos que usamos en producción, MariaDB. En este caso, haríamos tests contra el repositorio de usuarios que se conectaría con este contenedor. Usar esta imagen, aunque no sea “real”, nos da bastante confianza (por ser una imagen oficial) de que será muy similar al sistema real. Los tests serían del estilo “guardo esto en base de datos, le pido al repositorio que lo lea y compruebo que ha leído lo que guardé”.
En el caso de S3, nos gustaría poder hacer lo mismo. Subo una imagen a S3 a través de un servicio que implementamos nosotros y compruebo que la imagen está disponible. Sin embargo, en el caso de los servicios de AWS, no contábamos (al menos hasta donde sabíamos) con imágenes oficiales soportadas por AWS. Se nos ocurrieron dos opciones para testear la integración con S3:
-
Hacer los tests de integración contra un bucket real de S3.
Así nos aseguramos que usamos la API correctamente. Pero trae una serie de problemas, como que es un gasto extra en la factura de AWS y hay que tener en cuenta que se pueden pisar recursos compartidos si hay tests que ejecutan varias personas a la vez.
-
Usar contenedores no oficiales que simulan S3.
No hay recursos compartidos entre distintos desarrolladores y es gratis, pero corres el riesgo de que la imagen se desactualice o tengas configuraciones distintas en producción.
Nuestro primer test para conectar con S3
Para empezar optamos por usar una imagen Docker que simula S3, adobe/s3mock, en nuestros tests. Para ello, teníamos que configurar nuestro cliente de S3 para que apunte al endpoint de nuestro contenedor Docker e inyectarlo a nuestro servicio:
De esta forma el test de S3 queda muy sencillo. Lo único que hace es subir un fichero y comprobar que está disponible cuando intentamos descargarlo.
Luego hicimos otro test para comprobar que el borrado de imágenes funcionaba.
Suponiendo que la imagen de Docker se comporta igual que el S3 real, estos tests validan que usamos la API de S3 correctamente.
Sin embargo, algunos miembros del equipo no estaban del todo cómodos testeando únicamente en una imagen “falsa” de S3. Para mejorar el grado de confianza en los tests decidimos duplicar el test de subida de imágenes pero apuntado a un bucket de S3 real en AWS. De esta forma nuestra suite de test contiene tests para todas las posibles casuísticas contra la imagen de Docker de S3, y un único test contra el entorno real que nos sirve para comprobar que el sistema ha sido configurado correctamente.
Local rara vez se parece a staging o producción
Creíamos que estos tests nos daban la tranquilidad de de que todo iba a funcionar perfectamente. Sin embargo, cuando el equipo de sistemas nos pidió cambiar el bucket en el que guardábamos imágenes en el entorno de staging y producción, vimos que no era así.
Para asegurarnos de que no romperíamos nada al hacer ese cambio, decidimos hacer tests de configuración en producción porque este tipo de cambios de configuración suele ser más peligrosos que los cambios de código.
Estos “tests” se ejecutan con el código ya en producción, pero con una feature flag que nos permite ocultar los cambios a los usuarios. Por eso se denominan tests en la fase de deploy: el código está desplegado, pero aún no se ha “liberado” a los usuarios.
Utilizamos dos variables de entorno distintas para apuntar al bucket viejo y el nuevo. Metimos una feature flag que decidía qué variable usar y desplegamos. Activamos la feature flag en staging y, sorpresa, empezaron a fallar las subidas de imágenes.
Habíamos asumido que los tests contra la imagen de Docker era posible que dieran un falso positivo pero, ¿y el test que teníamos contra el bucket real?
Resulta que nos estábamos conectando, mediante credenciales de un usuario de IAM, a un bucket creado en el entorno de staging. En un punto, sistemas decidió cambiar esta forma de acceso porque no era una opción segura en producción, y pasamos a asignar permisos a través de un perfil a los pods de Kubernetes.
Con este cambio nuestros tests seguían funcionando, aunque el sistema en producción estaba roto. Los tests que se ejecutaban contra la imagen de S3 pasaban porque no apuntaban al sistema real, mientras que el test que apuntaba a un bucket real de S3 pasaba porque se conectaba de una forma distinta.
En este punto nos planteamos, ¿qué valor nos estaba aportando el test “real” si no se conectaba a S3 de la misma forma que se usaba en producción?
Concluimos que ninguno, así que tomamos la decisión de borrar el test que teníamos contra el entorno real de AWS y mantener solo los tests contra la imagen de Docker. De esta forma, sólo teníamos testeado si nuestra forma de interactuar con S3 era correcta, pero volvíamos a tener el inconveniente de quedar expuestos a posibles errores al cambiar la forma de establecer esa comunicación.
Cuantas más piezas tiene nuestro sistema más fácil es que alguna de ellas falle y necesitamos mecanismos que nos ayuden a detectar esos errores lo antes posible. Tener tests que ejecutamos en local o en una pipeline, o un entorno de staging para testear nos ayudan a reducir esos riesgos. Sin embargo, aunque pueden ser una muy buena imitación de la realidad, no dejan de ser sino una especie de placebo que nos da seguridad de que no se romperá en producción.
I’m more and more convinced that staging environments are like mocks - at best a pale imitation of the genuine article and the worst form of confirmation bias.
— Cindy Sridharan (@copyconstruct) March 16, 2018
It’s still better than having nothing - but “works in staging” is only one step better than “works on my machine”.
Testeando en producción
Ahora mismo, todos los tests se ejecutan en una pipeline que verifica que nuestro código es válido y, si lo es, se despliega en un entorno de staging. Esto nos protege de errores que hayamos cometido a la hora de programar pero, ¿qué pasa si por un error de configuración dejamos de tener acceso a ciertos recursos como puede ser base de datos o S3?
Independientemente del equipo que gestione los recursos de infraestructura, lo normal es que la configuración de esos recursos esté en un repositorio con un ritmo de cambio distinto y con unos tests que no tienen porqué cubrir todos nuestros casos de uso. Alguien podría borrar los permisos de acceso a un recurso para una aplicación, desplegar y no enterarnos hasta que empezamos a recibir errores de los usuarios.
La solución por la que hemos optado es chequear contínuamente en producción (y staging) que nuestro sistema tenga acceso a los recursos que necesita. Para ello, usamos un endpoint de health check. Kubernetes llama periódicamente a este endpoint y, en lugar de simplemente devolver un OK para decir que nuestra API está funcionando, aprovechamos para realizar una serie de comprobaciones adicionales. Por volver un poco a la terminología de Cindy, estaríamos haciendo tests release o post-release, ya que el código ya está disponible para los usuarios pero seguimos monitoreando posibles errores.
En el caso de S3, lo que haremos es subir una pequeña imagen, comprobar que si le hacemos una request nos da un 200 y luego borrarla. Esto nos da la seguridad de que en todo momento nuestra API tiene acceso a S3 en producción. No evitará que se produzcan errores en producción, pero sí nos avisará rápidamente del error, dando la posibilidad de que lo arreglemos incluso antes de que lo vean los usuarios.
Distintos tests, distintos beneficios
Resumiendo todo nuestro “viaje” hacia la tranquilidad de la integración con S3, al final, nos hemos quedado con tres tipos de tests.
-
Tests de integración locales contra una imagen de Docker. Son tests relativamente rápidos que nos dan la tranquilidad de que usamos el SDK de AWS de la forma correcta, y que se van a ejecutar en cada pipeline. Nos pueden proteger de subir a producción errores como URLs mal generadas o subir ficheros sin permisos de lectura o sin las cabeceras adecuadas.
-
Tests de configuración cuando haya que hacer cambios (config tests en fase de deploy). Si tenemos que cambiar la forma de conectarnos al bucket (o cambiar de bucket), duplicamos las configuraciones y decidimos una u otra en función de una feature flag. No nos protege de desplegar código con errores en producción, pero podemos desactivar ese código y volver a una configuración que funciona correctamente.
-
Health check de conexión con S3 (monitoring en fase de release o post-release). Es un test que se ejecutará periódicamente en staging y producción que comprobará que seguimos pudiendo hablar con S3 y que tenemos los permisos necesarios. No va a evitar que subamos errores a producción o que algún usuario pueda ver esos errores, pero tendremos una forma rápida de detectar esos errores y poder actuar en consecuencia.
Agradecimientos
Gracias a mis compañeros de Codesai por el feedback y al equipo de B2B de LifullConnect por las conversaciones que han servido para escribir este post.