De taxonomías y catálogos de code smells
Publicado por Manuel Rivero el 15/09/2022
Índice.
- Introducción: refactoring y code smells.
- Martin Fowler, Code Smells y Catálogos.
- Taxonomías
- Taxonomías de Wake 2003
- Taxonomía de Mäntylä et al 2003
- Taxonomía de Mäntylä et al 2006
- Taxonomía de Jerzyk et al 2022
- Conclusiones.
- Agradecimientos.
- Referencias.
Introducción: refactoring y code smells.
Refactorizar es una práctica que nos permite evolucionar un código de forma sostenible. Para poder hacerlo necesitamos, en primer lugar, ser capaces de reconocer el código problemático que necesita ser refactorizado.
Los code smells son descripciones de señales o síntomas que nos avisan de posibles problemas de diseño en nuestro código. Detectar estos problemas y eliminarlos tan pronto como uno se da cuenta de que hay algo mal es crucial.
El refactoring produce mejores resultados y es más barato si se hace con regularidad. Entre más tiempo permanezca sin refactorizar un código problemático, más se agravará su efecto y constreñirá el futuro desarrollo del código, contribuyendo directamente a la deuda técnica. Esta situación hará el código cada vez más difícil de mantener, lo que tendrá un impacto económico muy negativo, pudiendo incluso llegar, en el peor de los casos, a ser tan complicada que ya no se pueda seguir manteniendo el código.
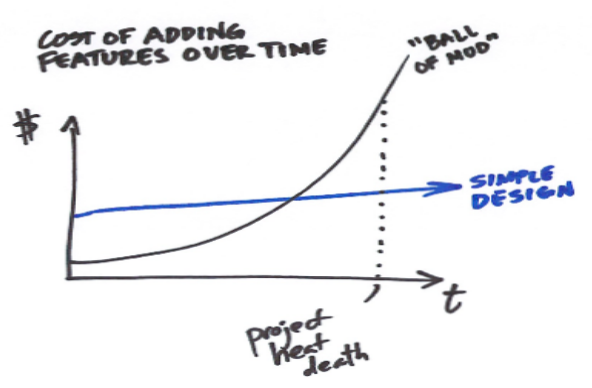
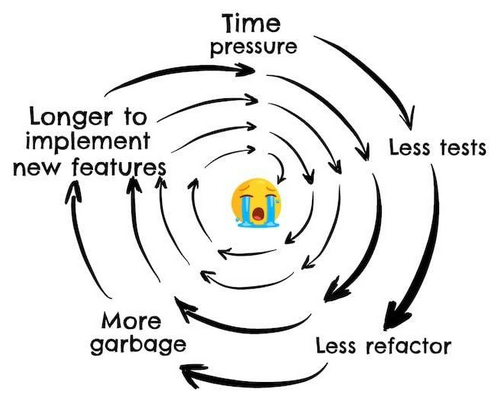
Otra consecuencia, a veces, no tan visible de la mala calidad del código es su efecto en los desarrolladores. Menos refactor, lleva a código menos mantenible, que nos lleva a tardar más tiempo en implementar nuevas funcionalidades, lo cuál nos mete más presión de tiempo, lo que nos lleva a testear menos, lo que nos lleva a refactorizar menos… Es un círculo vicioso que puede tener un efecto muy desmoralizador.
Por tanto, entender y saber identificar los code smells nos da mucho poder porque seremos capaces de detectar problemas de diseño cuando aún son pequeños y están muy localizados en zonas concretas de nuestro código, y eso tendrá un efecto económico y anímico muy positivo.
El problema es que los code smells no se suelen entender demasiado bien. Esto es entendible porque sus definiciones son a veces abstractas, difusas y abiertas a interpretación. Algunos code smells parecen obvios, otros no tanto, y algunos pueden enmascarar a otros code smells.
Además, recordemos que los code smells son sólo síntomas de posibles problemas, y no garantías de problemas. Para complicarlo aún más, además de los posibles falsos positivos, existen grados en el problema que cada smell representa, trade-offs entre smells y contraindicaciones en sus refactorings (en ocasiones “el remedio puede ser peor que la enfermedad”).
Por tanto, reconocer los code smells que señalan problemas de diseño, es decir, que no son falsos positivos, es una habilidad sutil, que requiere de experiencia y juicio. Adquirir esta habilidad, que a veces parece una especie de sentido arácnido, puede llevar tiempo.
En nuestra experiencia enseñando y acompañando a muchos equipos identificar code smells es una de las mayores barreras iniciales al refactoring. Muchos desarrolladores no se dan cuenta de los problemas del código que están generando cuando aún son pequeños. Lo que solemos ver es que no se dan cuenta hasta que los problemas son bastante grandes y/o se han combinado con otros problemas, propagándose por su base de código.
Catálogos de code smells.
En 1999 Fowler y Beck publicaron un catálogo de code smells en un capítulo del libro, Refactoring: Improving the Design of Existing Code. Este catálogo contiene las descripciones de 22 code smells.
En 2018 Fowler publicó una segunda edición de su libro. En esta nueva edición hay una serie de cambios con respecto a la primera, principalmente en el catálogo de smells y el catálogo de refactorings (que detalla en Changes for the 2nd Edition of Refactoring).
Si nos centramos en los smells, lo que nos interesa en este post, los cambios son los siguientes:
- Introduce cuatro code smells nuevos: Mysterious Name, Global Data, Mutable Data y Loops.
- Elimina dos smells: Parallel Inheritance Hierarchies y Incomplete Library Class.
- Renombra cuatro smells: Lazy Class pasa a ser Lazy Element, Long Method pasa a ser Long Function, Inappropriate Intimacy pasa a ser Insider Trading y Switch Statement pasa a ser Repeated Switches.
Quedan un total de 24 code smells, que aunque suelen tener nombres llamativos y memorables, son difíciles de recordar.
¿De qué manera podríamos entender mejor los code smells? ¿Cómo podríamos recordarlos más fácilmente?
En este post, y algunos posteriores, hablaremos de estrategias para profundizar, recordar y entender mejor los code smells.
Estrategias organizativas.
Organizar y manipular la información, verla desde diferentes puntos de vista, nos puede ayudar a entender y recordar mejor. Las taxonomías son un tipo de estrategia organizativa, que nos permite agrupar un material de estudio según su significado, creando agrupamientos significativos de información (“chunks”), que facilitarán el aprendizaje.
Como comentamos el catálogo de Fowler de 2018 es una lista plana que no proporciona ningún tipo de clasificación. Si bien, leyendo las descripciones de los de code smells, y las secciones de motivación de los diferentes refactorings podemos vislumbrar que algunos smells están más relacionados entre ellos que con otros smells, estas relaciones no se expresan de forma explícita y quedan difuminadas y dispersas en diferentes partes del libro.
El uso de taxonomías que clasifican code smells similares puede ser beneficioso para entenderlos mejor, recordarlos y reconocer las relaciones que existen entre ellos.
Taxonomías.
Ha habido diferentes intentos de clasificar los code smells agrupándolos según diferentes criterios. La clasificación más popular es la de Mäntylä et al 2006 pero no es la primera. A continuación mostraremos algunas que consideramos bastante interesantes.
Wake 2003.
Wake en su libro Refactoring Workbook de 2003 describe 9 nuevos code smells que no aparecían en el catálogo original de Fowler: Dead Code, Null Check, Special Case, Magic Number, Combinatorial Explosion, Complicated Boolean Expression, y tres relacionados con malos nombres: Type Embedded in Name, Uncommunicative Names e Inconsistent Names.
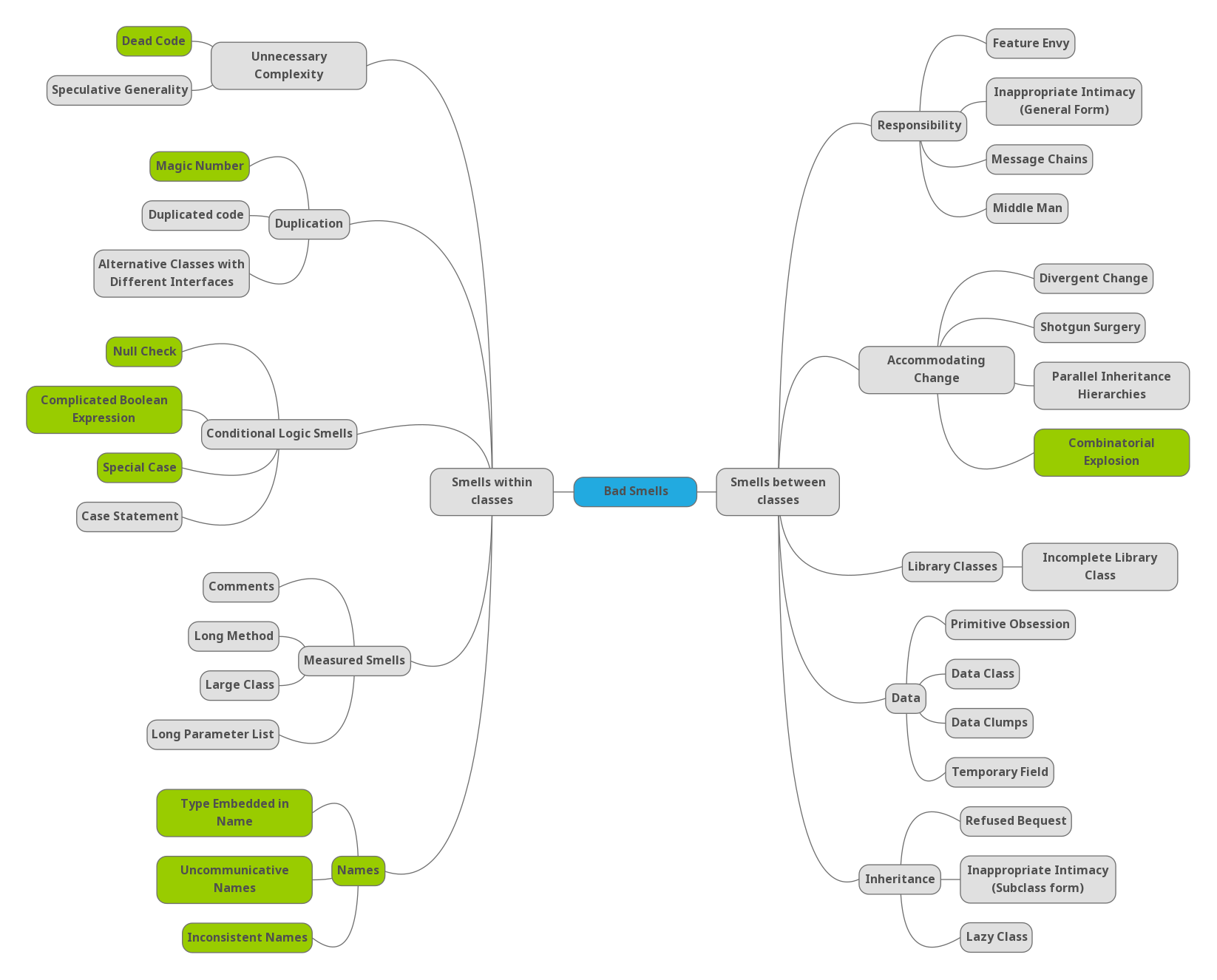
Wake clasifica explícitamente los code smells dividiéndolos primero en dos categorías amplias, Smells within Classes y Smells Between Classes, dependiendo, respectivamente, de si el code smell puede ser observado desde una clase o si se necesita considerar un contexto más amplio (varias clases). Cada una de estas categorías se divide en subcategorías que agrupan los code smells según en dónde se pueden detectar. Este criterio de clasificación, denominado más tarde “occurrence” por Jerzyk, responde a la pregunta: “¿dónde aparece este code smell?”.
Siguiendo este criterio Wake encuentra las siguientes 10 subcategorías.
Dentro de la categoría de Smells within Classes estarían las siguientes subcategorías:
- Measured Smells: code smells que pueden ser identificados fácilmente con simples métricas de longitud.
- Names: code smells que crean confusión semántica y afectan a nuestra capacidad de crear modelos mentales que nos ayuden a comprender, recordar y razonar sobre el código.
- Unnecessary Complexity: code smells relacionados con código innecesario que añade carga mental y complejidad. Código muerto, violaciones de YAGNI y complejidad accidental.
- Duplication: la némesis de los desarrolladores. Estos code smells provocan que haya mucho más código que mantener (carga cognitiva y física), aumentan la propensión a errores y dificultan la comprensión del código.
- Conditional Logic Smells: code smells que complican la lógica condicional haciendo difícil razonar sobre ella, dificultando el cambio y aumentando la propensión a cometer errores. Algunos de ellos son sucedáneos de mecanismos de la orientación a objetos.
Las subcategorías dentro de la categoría de Smells between Classes son:
- Data: code smells en los que encontramos, o bien pseudo objetos (estructuras de datos sin comportamiento), o bien encontramos que falta alguna abstracción.
- Inheritance: code smells relacionados con un mal uso de la herencia.
- Responsibility: code smells relacionados con una mala asignación de responsabilidades.
- Accommodating Change: code smells que se manifiestan cuando nos encontramos con mucha fricción al introducir cambios. Suelen estar provocados por combinaciones de otros code smells.
- Library Classes: code smells relacionados con el uso de librerías de terceros.
Wake presenta cada smell siguiendo un formato estándar con las siguientes secciones: Smell (el nombre y aliases), Síntomas (pistas que pueden ayudar a detectarlo), Causas (notas sobre cómo puede haberse generado), Qué Hacer (posibles refactorings), Beneficios (cómo mejorará el código al eliminarlo) y Contraindicaciones (falsos positivos y trade-offs). En algunos casos añade notas relacionando el code smell con principios de diseño que podrían ayudar a evitarlo.
El libro además contiene muchos ejercicios prácticos y tablas muy útiles (síntomas vs code smells, smells vs refactorings, refactorings inversos, etc) y ejercicios que relacionan los code smells con otros conceptos como principios de diseño o patrones de diseño.
Es un libro muy recomendable para profundizar en la disciplina de refactoring y entender mejor cuándo y por qué aplicar los refactorings que aparecen en el catálogo de Fowler.
Lo que enseñamos sobre code smells en nuestro curso sobre Code Smells & Refactoring se basa principalmente en esta clasificación de Wake aderezada con un poco de nuestra experiencia, aunque también hacemos referencia al resto de taxonomías de las que hablamos en este post.
Mäntylä et al 2003.
En ella los code smells se agrupan según el efecto que tienen en el código (el tipo de problema, lo que hacen difícil o las prácticas o principios que rompen). Jerzyk 2022 denomina “obstrucción” a este criterio de clasificación.
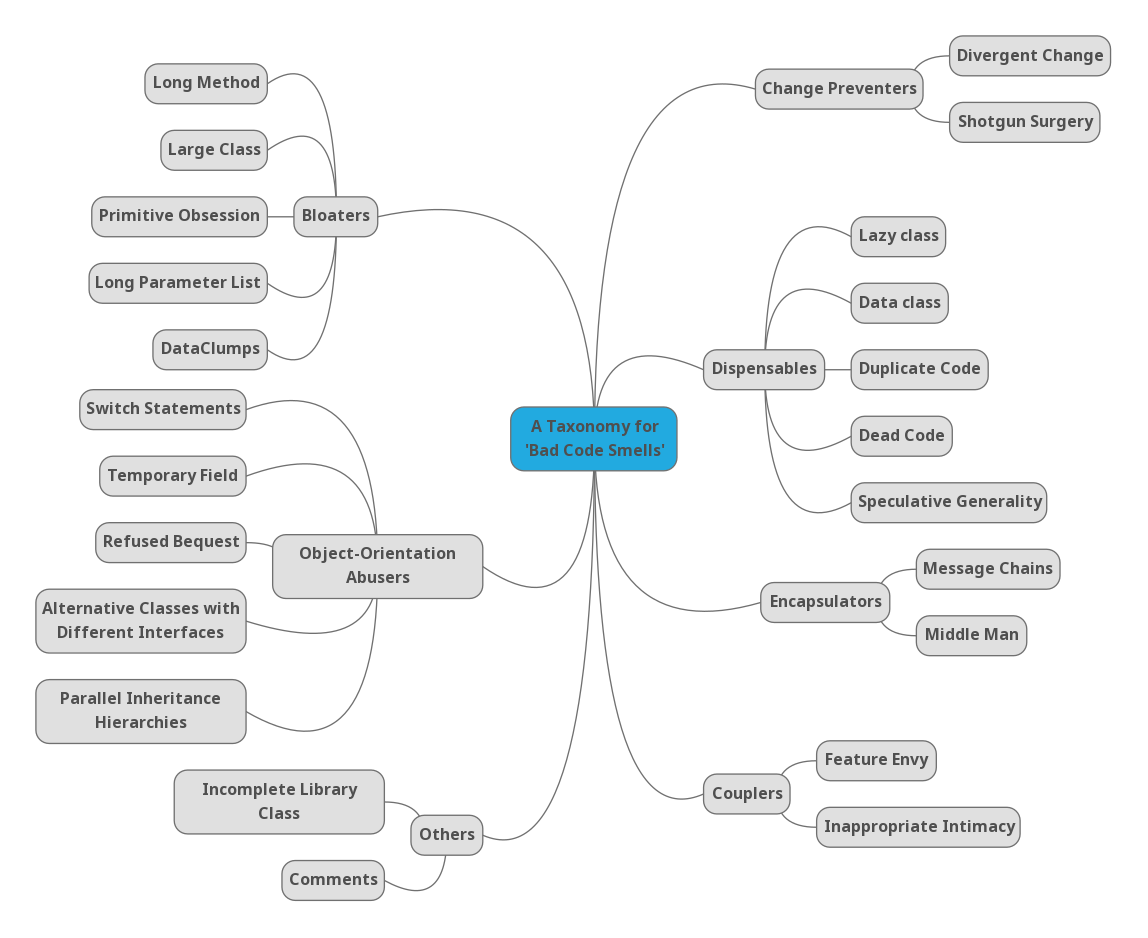
En la clasificación original de 2003 (A Taxonomy and an Initial Empirical Study of Bad Smells in Code) había 7 categorías de code smells: Bloaters, Object-Orientation Abusers, Change Preventers, Dispensables, Encapsulators, Couplers y Others.
Así es como definen cada una de las categorías (disculpen al traductor…):
- Bloaters: “representan algo en el código que ha crecido tanto que ya no se puede manejar de forma efectiva.“
- Object-Orientation Abusers: “esta categoría de smells se relaciona con casos en los que la solución no explota completamente las posibilidades del diseño orientado a objetos.”
- Change Preventers: “esta categoría hace referencia a estructuras de código que dificultan considerablemente cambiar el software.”
- Dispensables: “estos smells representan algo innecesario que debería ser eliminado del código.”
- Encapsulators: “tiene que ver con mecanismos de comunicación o encapsulación de datos.”
- Couplers: “estos smells representan casos de acoplamiento alto, lo cual va en contra de los principios de diseño orientado a objetos”
- Others: “esta categoría contiene los code smells restantes (Comments e Incomplete Library Class) que no encajaban en ninguna de las categorías anteriores.”
En el artículo, Mäntylä et al discuten los motivos por los que incluyeron cada smell en una determinada categoría y no otra, aunque admiten que algunos de ellos podrían ser clasificados en más de una categoría.
Mäntylä et al 2006.
En 2006 Mäntylä et al sacaron otro artículo (Subjective evaluation of software evolvability using code smells: An empirical study) en el que revisaron su clasificación original de 2003.
La diferencia de esta nueva versión es que elimina las categorías Encapsulators (moviendo los smells Message Chains y Middle Man a la categoría Couplers) y Others (Comments e Incomplete Library Class desaparecen de la taxonomía), y mueve el code smell Parallel Inheritance Hierarchies de la categoría de Object-Orientation Abusers a la categoría de Change Preventers.
Esta última versión de su taxonomía es la que se ha hecho más popular en internet (se puede encontrar en muchas webs, cursos y posts), probablemente debido a la mayor accesibilidad (facilidad de lectura) del resumen del artículo que aparece en la web que resume el artículo: A Taxonomy for “Bad Code Smells”.
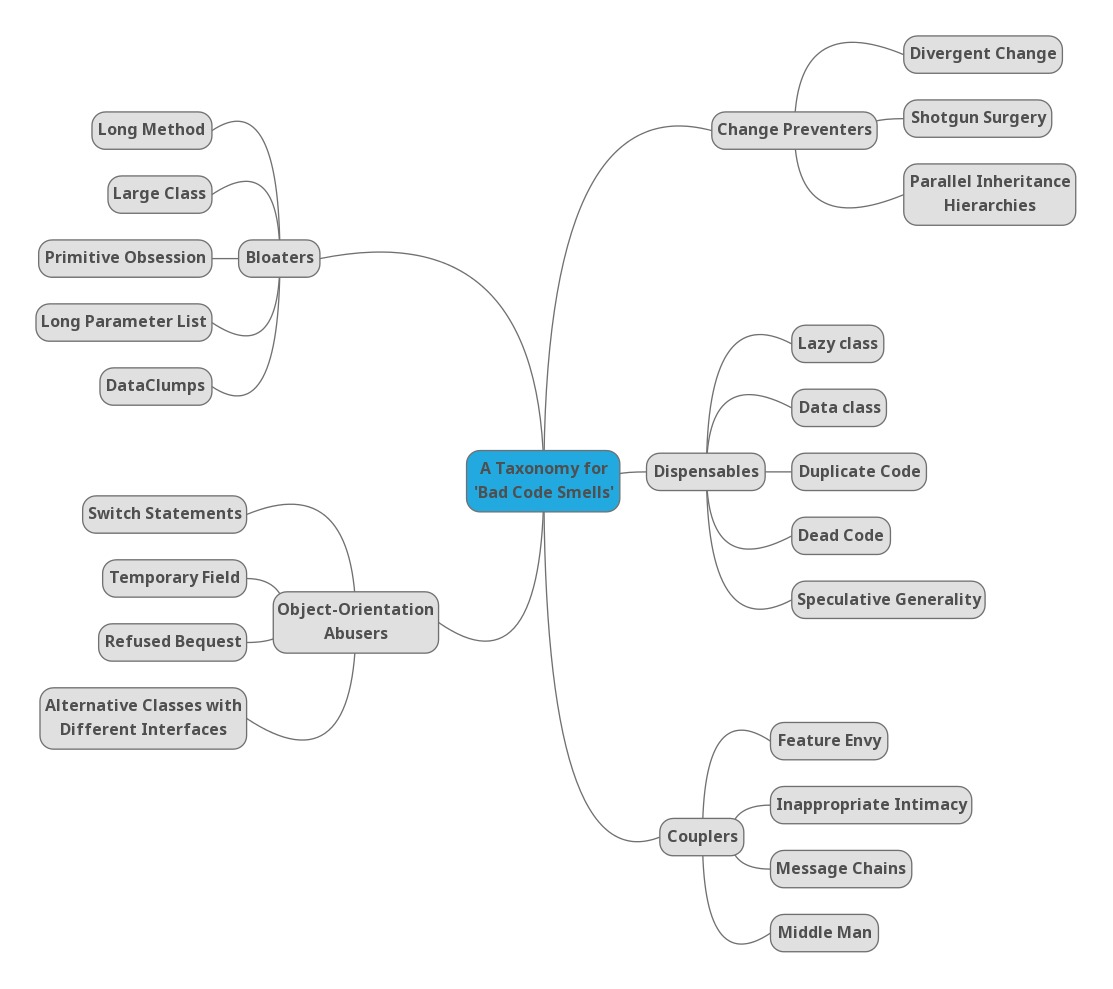
Lo interesante no es tanto la discusión de en qué categoría debe caer cada smell, sino el empezar a pensar qué un determinado smell puede tener diferentes tipos de efectos en el código y las relaciones entre estos efectos. De hecho, en posteriores clasificaciones desde el punto de vista del efecto de un smell en el código, no consideran ya las categorías como excluyentes, sino que, un mismo smell puede caer en varias categorías, ya que consideran que es más útil no perder la información de que un smell puede producir varios efectos.
Jerzyk et al 2022.
En 2022 Marcel Jerzyk publicó su tesis de master, Code Smells: A Comprehensive Online Catalog and Taxonomy y un artículo con el mismo título. Su investigación sobre code smells tenía tres objetivos:
- Proporcionar un catálogo público que pudiera ser útil como una base de conocimiento unificada tanto para investigadores como para desarrolladores.
- Identificar todos los conceptos posibles que están siendo caracterizados como code smells y determinar posibles controversias sobre ellos.
- Asignar propiedades apropiadas a los code smells con el fin de caracterizarlos.
Para conseguir estos objetivos realizaron una revisión de la literatura existente hasta ese momento sobre code smells, haciendo especial énfasis en las taxonomías de code smells.
En su tesis identifican y describen 56 code smells, de los cuales 16 son propuestas originales suyas, (recordemos que Wake describió 31 code smells y Fowler 24 en su última revisión). En la tesis de master de Jerzyk se pueden encontrar descripciones y discusiones sobre cada uno de estos 56 code smells.
Analizando los criterios de clasificación de las taxonomías propuestas anteriormente, Jerzyk encuentra tres criterios significativos para categorizar code smells:
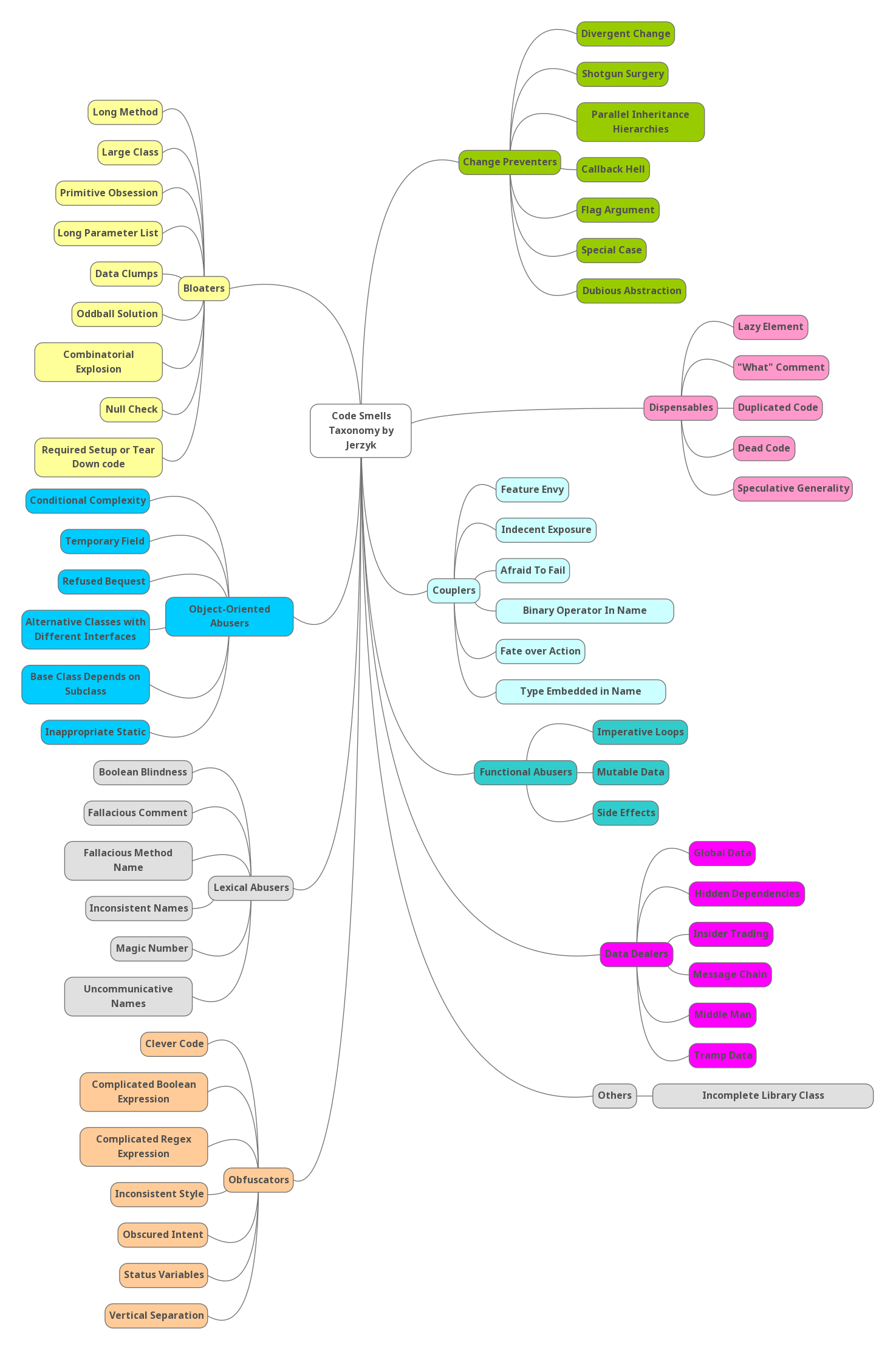
- Obstruction: Este es el criterio usado por Mäntylä et al para clasificar los smells en su taxonomía y el más popular. Este criterio nos informa sobre el tipo de problema que un code smell causa en el código (lo que hacen difícil o las prácticas o principios que rompen). En la tesis actualizan la taxonomía de Mäntylä, añadiendo tres nuevos grupos: Data Dealers, Functional Abusers y Lexical Abusers. A continuación presentamos un mapa mental que muestra la clasificación de los 56 code smells siguiendo únicamente este criterio.
-
Expanse: Inspirado por la taxonomía de Wake, este criterio habla de si el code smell puede ser observado en un contexto reducido (dentro de una clase) o si se necesita considerar un contexto más amplio (entre varias clases). Las posibles categorías son Within Class y Between Classes.
-
Occurrence: También inspirado por la taxonomía de Wake, este criterio está relacionado con la localización donde (o el método por el cuál) se puede detectar un code smell. Las posibles categorías son Names, Conditional Logic, Message Calls, Unnecessary Complexity, Responsibility, Interfaces, Data, Duplication y Measured Smells.
A continuación presentamos una tabla con los 56 code smells clasificados por Jerzyk en su tesis usando los tres criterios comentados anteriormente:
| Code Smell | Obstruction | Expanse | Occurrence |
|---|---|---|---|
| Long Method | Bloaters | Within | Measured Smells |
| Large Class | Bloaters | Within | Measured Smells |
| Long Parameter List | Bloaters | Within | Measured Smells |
| Primitive Obsession | Bloaters | Between | Data |
| Data Clumps | Bloaters | Between | Data |
| Null Check | Bloaters | Between | Conditional Logic |
| Oddball Solution | Bloaters | Between | Duplication |
| Required Setup/Teardown | Bloaters | Between | Responsibility |
| Combinatorial Explosion | Bloaters | Within | Responsibility |
| Parallel Inheritance Hierarchies | Change Preventers | Between | Responsibility |
| Divergent Change | Change Preventers | Between | Responsibility |
| Shotgun Surgery | Change Preventers | Between | Responsibility |
| Flag Argument | Change Preventers | Within | Conditional Logic |
| Callback Hell | Change Preventers | Within | Conditional Logic |
| Dubious Abstraction | Change Preventers | Within | Responsibility |
| Special Case | Change Preventers | Within | Conditional Logic |
| Feature Envy | Couplers | Between | Responsibility |
| Type Embedded In Name | Couplers | Within | Names |
| Indecent Exposure | Couplers | Within | Data |
| Fate over Action | Couplers | Between | Responsibility |
| Afraid to Fail | Couplers | Within | Responsibility |
| Binary Operator in Name | Couplers | Within | Names |
| Tramp Data | Data Dealers | Between | Data |
| Hidden Dependencies | Data Dealers | Between | Data |
| Global Data | Data Dealers | Between | Data |
| Message Chain | Data Dealers | Between | Message Calls |
| Middle Man | Data Dealers | Between | Message Calls |
| Insider Trading | Data Dealers | Between | Responsibility |
| Lazy Element | Dispensables | Between | Unnecessary Complexity |
| Speculative Generality | Dispensables | Within | Unnecessary Complexity |
| Dead Code | Dispensables | Within | Unnecessary Complexity |
| Duplicate Code | Dispensables | Within | Duplication |
| “What” Comments | Dispensables | Within | Unnecessary Complexity |
| Mutable Data | Functional Abusers | Between | Data |
| Imperative Loops | Functional Abusers | Within | Unnecessary Complexity |
| Side Effects | Functional Abusers | Within | Responsibility |
| Uncommunicative Name | Lexical Abusers | Within | Names |
| Magic Number | Lexical Abusers | Within | Names |
| Inconsistent Names | Lexical Abusers | Within | Names |
| Boolean Blindness | Lexical Abusers | Within | Names |
| Fallacious Comment | Lexical Abusers | Within | Names |
| Fallacious Method Name | Lexical Abusers | Within | Names |
| Complicated Boolean Expressions | Obfuscators | Within | Conditional Logic |
| Obscured Intent | Obfuscators | Between | Unnecessary Complexity |
| Vertical Separation | Obfuscators | Within | Measured Smells |
| Complicated Regex Expression | Obfuscators | Within | Names |
| Inconsistent Style | Obfuscators | Between | Unnecessary Complexity |
| Status Variable | Obfuscators | Within | Unnecessary Complexity |
| Clever Code | Obfuscators | Within | Unnecessary Complexity |
| Temporary Fields | O-O Abusers | Within | Data |
| Conditional Complexity | O-O Abusers | Within | Conditional Logic |
| Refused Bequest | O-O Abusers | Between | Interfaces |
| Alternative Classes with Different Interfaces | O-O Abusers | Between | Duplication |
| Inappropriate Static | O-O Abusers | Between | Interfaces |
| Base Class Depends on Subclass | O-O Abusers | Between | Interfaces |
| Incomplete Library Class | Other | Between | Interfaces |
Algunos de los nombres en la tabla son diferentes de los que suelen aparecer en la literatura. Los cambios de nombre fueron debidos a la introducción de nombre más actualizados, como es el caso, por ejemplo, de Lazy Element o Insider Trading que antes se llamaban Lazy Class e Inappropriate Intimacy, respectivamente.
Hay varios smells que son nuevos. Algunos como Afraid to Fail, Binary Operator in Name, Clever Code, Inconsistent Style, y Status Variable, son ideas completamente nuevas. Otros son conceptos ya existentes en la literatura pero que no se habían considerado en el contexto de los code smells: Boolean Blindness o Callback Hell. Tres de ellos proponen alternativas para code smells que están siendo cuestionados en la literatura: “What” Comment como alternativa para Comments, Fate over Action como alternativa para Data Class, e Imperative Loops como alternativa para Loops (ver la tesis de Jerzyk para profundizar en por qué estos code smells originales son discutibles). Otros generalizan otros conceptos problemáticos que han surgido en la literatura: Complicated Regex Expression, Dubious Abstraction, Fallacious Comment, Fallacious Method Name. Por último, un problema conocido (especialmente en el campo de la programación funcional), pero que no se ha considerado hasta ahora como code smell: Side Effects.
Una cosa super útil y práctica para desarrolladores que aporta el trabajo de Jerzyk es la creación de un catálogo online de code smells que incluía cuando se publicó los 56 code smells que aparecen en la tabla. Este catálogo es un sitio web accesible y buscable. En la fecha de publicación de este post, el catálogo contiene 56 code smells.
En el catálogo se pueden buscar los smells por diferentes criterios de clasificación.
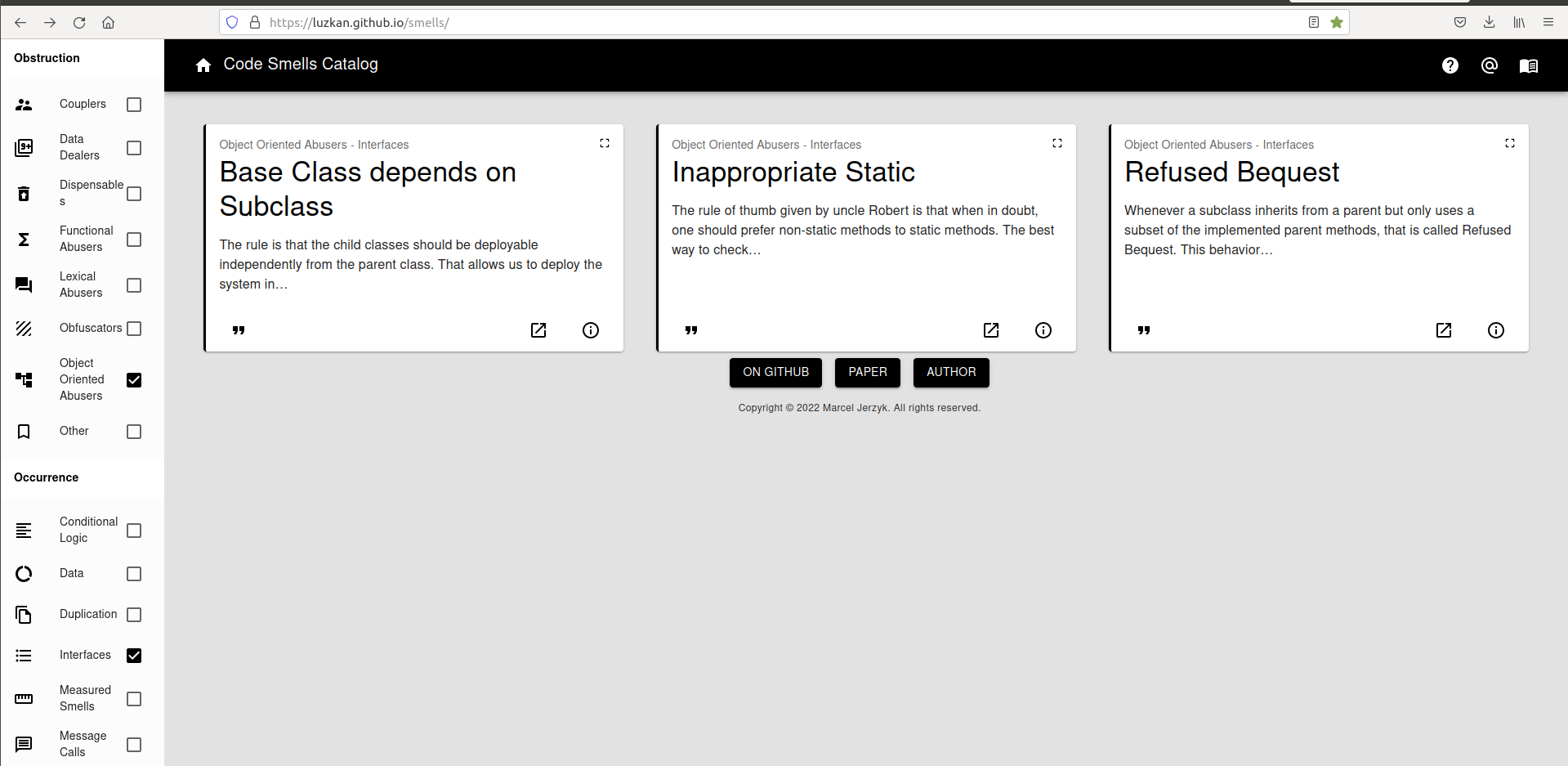
Por ejemplo, esta captura de pantalla muestra el resultado de buscar code smells que sean OO Abusers y que afecten a Interfaces: Refused Bequest, Base Class depends on Subclass e Inappropriate Static.
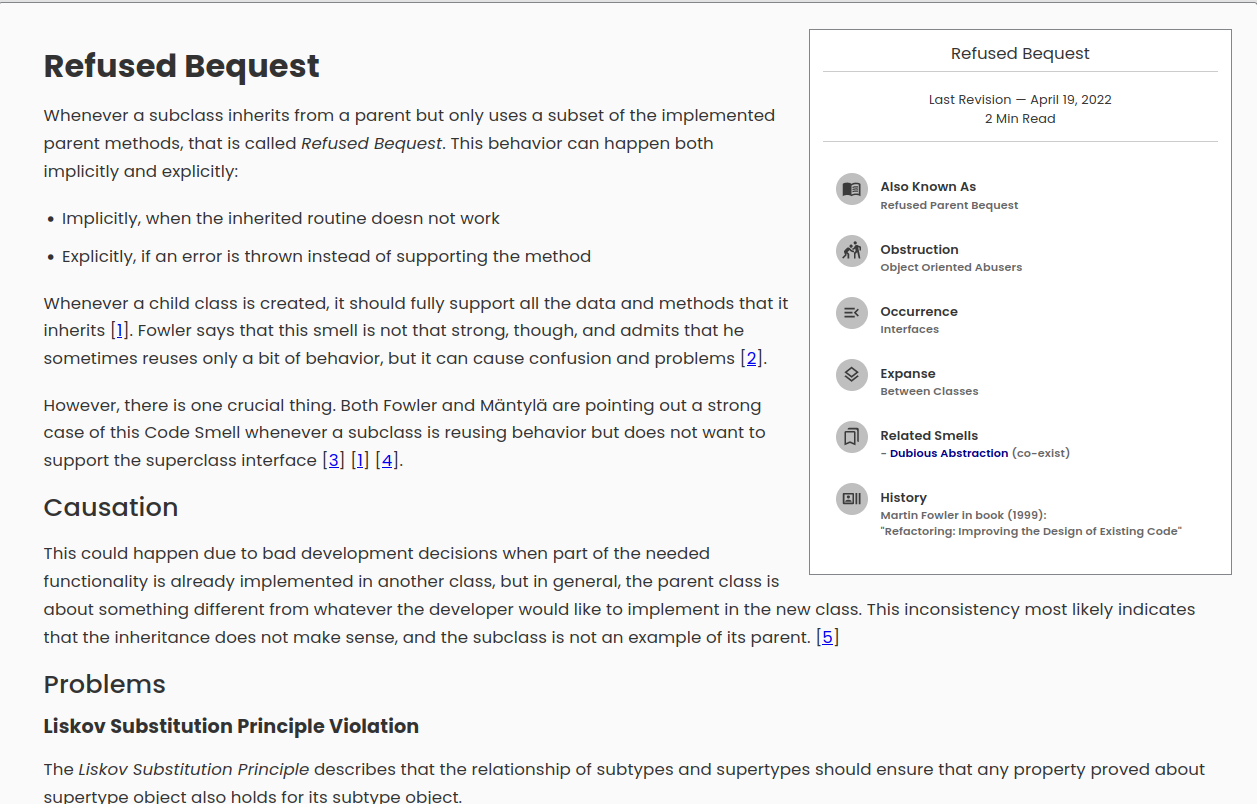
Para cada smell el catálogo presentan las siguientes secciones: Smell (discusión del smell), Causation (posibles causas del code smell), Problems (problemas que el smell puede causar o principios de diseño que viola), Example (ejemplos de código mínimo que ilustran los posibles síntomas de un code smell y muestran una posible solución), Refactoring (posibles refactorings) y Sources (artículos o libros en los que se ha hablado de este code smell). También incluye un recuadro en el que aparece información sobre posibles aliases del code smell, la categoría a la que pertenece según los criterios de obstruction, occurrence y expanse, los smells relacionados y su relación con ellos, y el origen histórico del code smell.
Conclusiones.
Desde que se acuñó el concepto de code smell en 1999 han aparecido muchos nuevos smells. Las presentaciones planas en forma de catálogo son difíciles de recordar, y no ayudan a resaltar las relaciones que existen entre diferentes code smells.
Hemos presentado varias taxonomías de code smells que nos pueden ayudar a ver los code smells desde diferentes puntos de vista y relacionarlos unos con otros según diferentes criterios: los problemas que producen en el código, dónde se detectan o el contexto que es necesario tener en cuenta para detectarlos.
Estos agrupamientos significativos de code smells nos ayudarán a entenderlos y a recordarlos mejor que las listas planas de los catálogos.
Por último queremos destacar el reciente trabajo de Marcel Jerzyk que no sólo ha propuesto nuevos smells y ha creado una nueva taxonomía multicriterio, sino que además ha puesto a nuestra disposición un catálogo online de code smells en forma de repositorio open-source y sitio web accesible y buscable, que creemos que puede resultar muy útil y práctico tanto para investigadores como para desarrolladores. Los animo a echarle un vistazo.
Agradecimientos.
Me gustaría darle las gracias a mis colegas Fran Reyes, Antonio de La Torre, Miguel Viera y Alfredo Casado por leer los borradores finales de este post y darme feedback. También quería agradecer a nikita por su foto.
Referencias.
Libros.
- Refactoring: Improving the Design of Existing Code 1st edition 1999, Martin Fowler et al.
- Refactoring: Improving the Design of Existing Code 2nd edition 2018, Martin Fowler et al.
- Refactoring Workbook, William C. Wake
- Refactoring to Patterns, Joshua Kerievsky
- Five Lines of Code: How and when to refactor, Christian Clausen
- The Programmer’s Brain, Felienne Hermans
Artículos.
- A Taxonomy and an Initial Empirical Study of Bad Smells in Code, Mantyla et al, 2003.
- Subjective evaluation of software evolvability using code smells: An empirical study, Mantyla et al, 2006.
- A Taxonomy for “Bad Code Smells” , Mantyla et al, 2006.
- Code Smells: A Comprehensive Online Catalog and Taxonomy, Marcel Jerzyk, 2022.
- Code Smells: A Comprehensive Online Catalog and Taxonomy Msc. Thesis, Marcel Jerzyk, 2022.
- Extending a Taxonomy of Bad Code Smells with Metrics, R. Marticorena et al, 2006
Foto de nikita in Pexels