Un caso de Shotgun Surgery
Publicado por Fran Reyes & Manuel Rivero el 12/09/2022
Colaboramos con un cliente en cuyo producto, el SEO es un aspecto muy importante del negocio. En general, el SEO suele ser un aspecto a cuidar, pero en el caso de este cliente el SEO supone una fuente de ingresos considerable.
Cuando los buscadores analizan las páginas de un producto hay 2 partes importantes para nuestro sistema que se deben indicar al buscador, la indexación de esa página y su canonical.
Ante páginas similares, el canonical le indica al buscador cuál página queremos posicionar (mediante su url). De esta manera evitamos que los motores de búsqueda nos penalicen al considerar dichas páginas similares como contenido duplicado.
En el contexto del producto, el SEO además de ser una fuente de ingresos importante, es bastante complejo. Es decir, partimos de una complejidad esencial contenida en reglas de negocio, con una gran variedad de reglas de comportamiento dependiendo de aspectos como la ubicación, el número de resultados, el tipo de búsqueda, etc.
Situación del código
A la complejidad esencial de calcular el canonical de una página y decidir si se indexa o no, se añadía la complejidad accidental provocada por un código en el que las reglas del SEO se encontraban dispersas en 2 zonas de la aplicación, IndexationCalculator y CanonicalCalculator. Por suerte, ambas tenían tests.
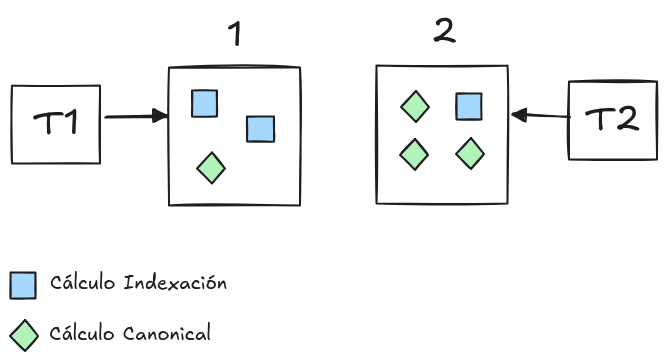
Los clientes veían estas 2 funcionalidades a través de las interfaces que se muestran a continuación:
El problema
Viendo los nombres de las interfaces, IndexationCalculator y CanonicalCalculator, parece que la responsabilidad de saber si una página se indexa y calcular el canonical están bien segregadas. Sin embargo, cuando se nos pide, por ejemplo, cambiar un aspecto del cálculo del canonical nos vemos obligados a considerar y probablemente cambiar tanto la implementación de IndexationCalculator como CanonicalCalculator.
Es decir, el problema es que si nos piden hacer cambios concretos nos vemos obligados a tocar múltiples zonas. El código presenta un caso claro de un code smell conocido como Shotgun Surgery.
El Shotgun Surgery es una violación del principio de única responsabilidad. En este caso concreto existe una falta de cohesión a nivel de implementación. Es decir, si bien los ejes de cambio se identificaron correctamente a nivel de interface, las responsabilidades se distribuyeron mal, quedando repartidas entre ambas implementaciones[1].
La solución para resolver el Shotgun Surgery es segregar las responsabilidades de manera que no violemos el principio de única responsabilidad. Para ellos necesitamos mover código hacia el lugar donde debería habitar, pero esto no es tan fácil como usar el refactoring Move Function.
El problema es que en este caso las reglas se estaban ejecutando en un orden determinado y eso no estaba ni en IndexationCalculator ni en CanonicalCalculator sino en el código cliente. Además, ese orden, determinado por el cliente, no estaba testeado.
Segregando las Reglas
En un caso en el que el cálculo del canonical y el de la indexación no tuvieran que ser ejecutadas en un orden determinado, mover las reglas sólo supondría mover casos de tests entre los tests de las implementaciones y el mover el código correspondiente, usando Move Function.

Pero, como explicamos anteriormente, la dependencia entre ambos cálculos introducida por el orden preestablecido y la complejidad de las reglas, hacía que no fuera fácil razonar si era seguro mover la lógica sin cambiar comportamiento. Además, teniendo en cuenta, como ya se explicó, que el SEO supone una fuente de ingresos considerable para este producto, no podíamos aceptar el nivel de riesgo que suponía refactorizar de la manera que hemos explicado.
Para reducir el riesgo de modificar el comportamiento, lo que hicimos fue extraer una clase, llamada PageIndexer, cuya responsabilidad era coordinar los cálculos de la indexación y el canonical.
A continuación creamos una nueva batería de tests contra PageIndexer que contenía los casos de tests tanto del CanonicalCalculator como de IndexationCalculator, y añadimos los tests que faltaban para la interacción entre ambas clases. De esta manera estábamos probando no solo cada unidad por separado sino además la interacción (o integración) de ambas.
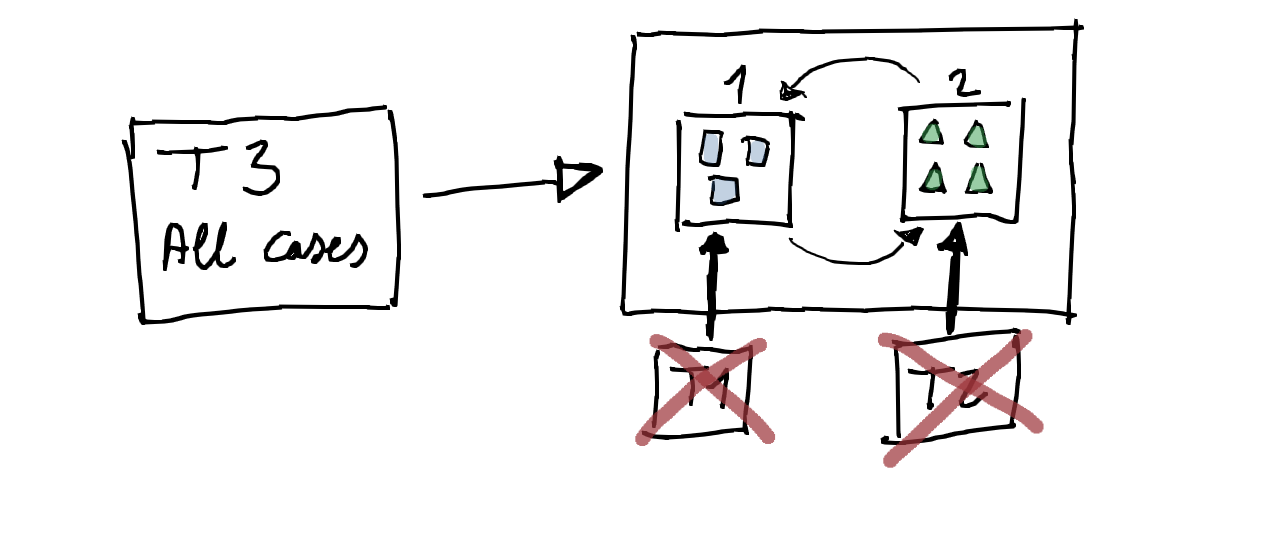
Teniendo estos tests contra PageIndexer pudimos empezar a mover a IndexationCalculator la lógica de indexation que se había filtrado en CanonicalCalculator y viceversa. Para ello movimos las reglas moviendo primero los casos de tests y luego el código correspondiente, usando Move Function. Al terminar de segregar las responsabilidades, eliminamos los tests que probaban las responsabilidades por separado.
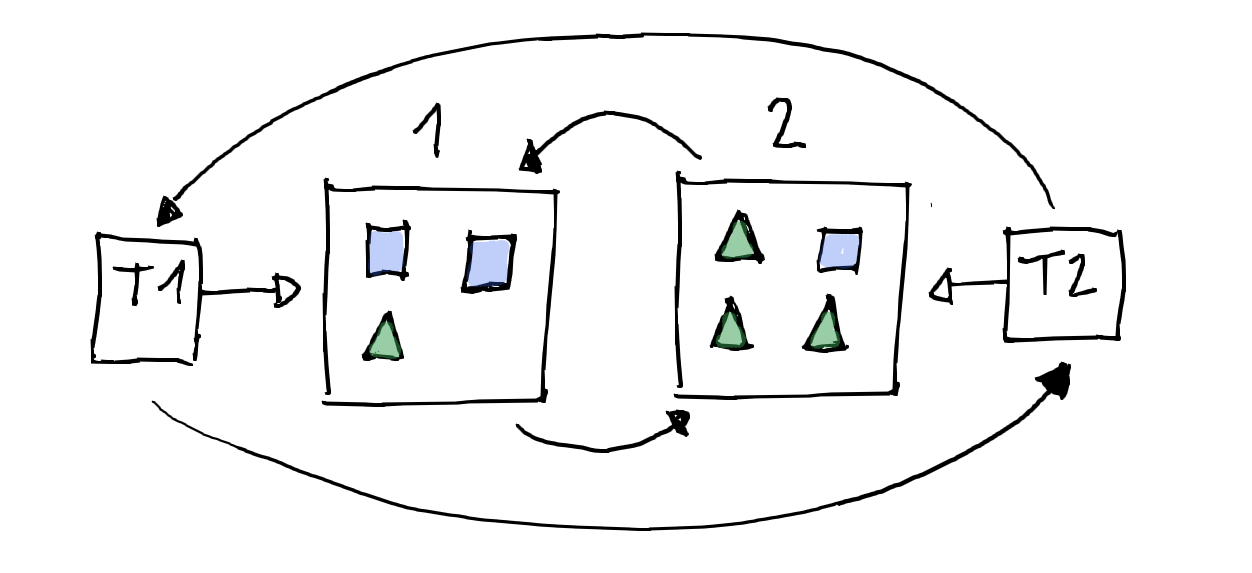
Conclusión
Hemos presentado un caso de Shotgun Surgery a partir de un caso real y hemos contado como se hizo refactoring para segregar las responsabilidades.
En un contexto sin las particularidades comentadas, los pasos para resolver el problema habrían dado menos trabajo. Pero el orden de ejecución, la complejidad y el alto valor de negocio en este contexto, hicieron que tuviéramos que trabajar más y no seguir la manera canónica descrita en la mayoría de literatura.
Si te encuentras en una situación parecida, quizás puedes aplicar algunos de los aspectos de esta solución y reducir el riesgo del cambio.
Notas
[1] Los motivos por los que se produjo una mezcla de las responsabilidades pueden estar en el diseño de las interfaces, pero este problema quizás lo tratemos en un futuro post.