Mutando para simplificar
Publicado por Rubén Díaz el 11/02/2022
Una de las herramientas que mencionamos en nuestro curso de TDD es mutation testing[1]. Para quien no esté familiarizado, es una herramienta que, en líneas generales, lanza nuestra batería de tests haciendo modificaciones (mutaciones) del código de producción que introducen defectos. Si un test falla, significa que nuestros tests protegen contra el defecto introducido (o en términos de mutation testing, nuestros tests matan al mutante). En cambio, si todos los tests pasan, significa que los tests no protegían contra el defecto introducido.
Personalmente, el mutation testing no es algo que use a diario, pero sí que es valioso conocer su existencia si te encuentras en el caso de que necesitas cambiar una zona de código sensible en la que un bug supondría perder mucho dinero.
Un ejemplo muy sencillo que puede servir para mostrar su potencia es cuando estamos haciendo comprobaciones de rangos de números. Por ejemplo, en la kata ohce hay una parte de la funcionalidad que saluda de diferentes maneras según la hora del día:
- Entre las 20 y las 6, ohce te dirá ¡Buenas noches!
- Entre las 6 y las 12, ohce dirá ¡Buenos días!
- Entre las 12 y las 20, dirá ¡Buenas tardes!
Si no tenemos cuidado al testear estos rangos, podemos acabar con una batería de tests en verde que pruebe que si son las 8 te dice ¡Buenos días!, si son las 14 te responde ¡Buenas tardes! y a las 23 ¡Buenas noches!. Con estos tres casos, tendremos los tests en verde y 100% de cobertura, genial, ¿verdad?
Seguridad infundada
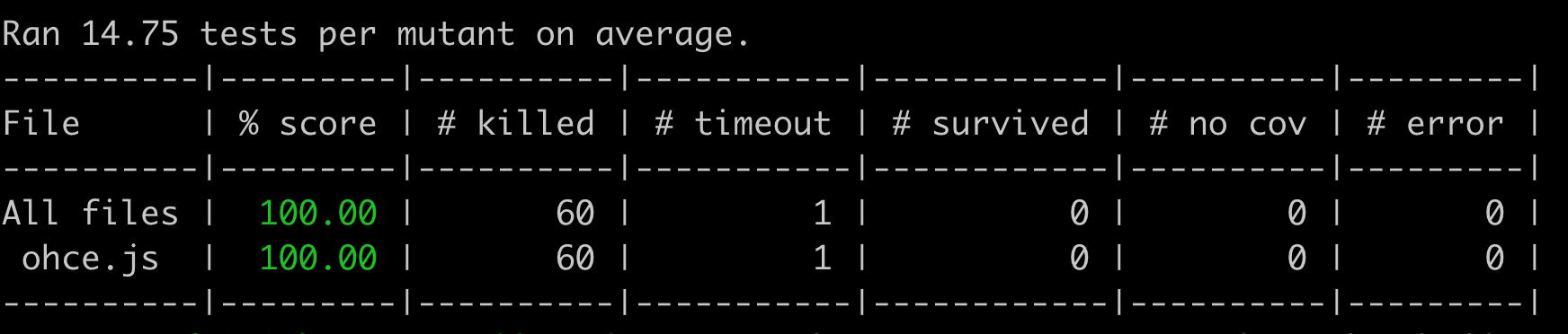
Si ejecutasemos una herramienta de mutation testing como Stryker, nos encontraríamos la sorpresa de que 6 mutaciones en nuestro código sobrevivirían a los casos de prueba que tenemos definidos ahora mismo.

En la figura de arriba podemos ver una sección del informe que genera Stryker. Nos está marcando que en ese if ha hecho 3 mutaciones que han sobrevivido, siendo una de ellas el cambiar un >= por >. ¿Por qué ha pasado esto? Porque nuestros tests solamente estaban fijando un valor en el interior del rango, el número 8, y no sus extremos.
Si cambiamos los tests de forma que fijen los extremos de los rangos y volvemos a ejecutar Stryker, comprobaremos que no sobrevivirá ninguna mutación.
Simplificando nuestro código
Hasta ahora hemos visto cómo mutation testing nos puede ayudar a encontrar aquellos tests que hemos olvidado hacer. Ahora me gustaría hablar de un caso particular que nos encontramos recientemente en una sesión de práctica deliberada con la gente de Audiense.
Cuando una de las parejas estaba usando mutation testing para comprobar que habían hecho todos los tests necesarios para cuadrar el rango de horas, esperábamos encontrar una lista de mutantes parecida a la que aparece en la figura de más arriba. Sin embargo, nos encontramos con que había sobrevivido un único mutante:

Resulta que la condición de hour >= 6 era innecesaria, ya que la mutación introducida al cambiar dicho código por true sobrevivía (los tests seguían pasando). Pero revisamos los tests y estaban “bien” así que, ¿qué está pasando?
Si nos paramos a pensar un poco, debido a cómo están estructurados los ifs, entraremos en el primer caso si la hora es mayor igual que 20 o menor que 6. Si esta condición es falsa, significa que la hora es menor que 20 y mayor o igual que 6, así que la condición que tenemos de hour >= 6 siempre va a ser true.
Sabiendo esto, podemos decidir “simplficar” el código y dejar la condición en el segundo if simplemente como hour < 12. Cabría preguntarse si este cambio merece la pena o no. A mi de entrada me pareció buena idea, todo lo que sea borrar código siempre me parece bien. El código quedaría así:
Sin embargo, el código resultante no será fácil de entender para la gente que tendrá que mantenerlo. Aunque podríamos sacar funciones privadas para mejorar su comprensión de las condiciones de los ifs, hemos hecho que el orden de ejecución de los ifs sea importante. Imaginemos que alguien modifica el orden de las comprobaciones. Si el if de los “Buenos días” lo pusiéramos el primero, romperíamos los tests, porque haríamos que para las 4 de la mañana diga Buenas noches en lugar de Buenos días[3].
Para evitar estos problemas seguramente decidiría no borrar la condición innecesaria e ignorar el mutante que ha sobrevivido. Otra opción podría ser refactorizar el código para que los ifs estén en el mismo orden que vimos en la primera solución de la kata, lo cual, no dejaría sobrevivir a ningún mutante.
Conclusión
Como hemos visto, mutation testing es una herramienta muy útil que nos puede ayudar a encontrar tests que se nos han olvidado y asegurar más nuestro código en las zonas más críticas. Configurarlo para nuestro proyecto es relativamente sencillo (al menos ese es el caso con Stryker en Javascript o PIT en Java), pero tenemos que saber interpretar los datos que nos da y decidir si debemos añadir tests, o bien modificar nuestro código para que mate todas las mutaciones sin perder legibilidad.
Agradecimientos
Me gustaría agradecer a mi compañero Manuel Rivero por invitarme a impartir varias sesiones de práctica deliberada con él donde me pude encontrar con este caso, y a la gente de Audiense por su asistencia, especialmente a Iván Portillo y Roberto Segura porque fue con ellos con quién vimos este curioso caso de mutation testing. Y por último, gracias a mis compañeros de Codesai por el feedback en este post.
Notas
[1] En este otro post hablamos también de mutation testing para el desarrollo de la librería reffects.
[2] En el informe aparece un timeout porque en el código de la kata hay un bucle que al cambiar una condición se convierte en un bucle infinito y los tests no terminan de ejecutarse.
[3] Aquí tendríamos un ejemplo de Connascence of Execution.