On code smells catalogues and taxonomies
Published by Manuel Rivero on 05/11/2022
This post is an English translation of the original post: De taxonomías y catálogos de code smells.
Index.
- Introduction: code smells and refactoring.
- Martin Fowler: code smells and catalogues.
- Taxonomies.
- Wake’s taxonomy 2003.
- Mäntylä et al taxonomy 2003.
- Mäntylä et al taxonomy 2006.
- Jerzyk et al taxonomy 2022.
- Conclusions.
- Acknowledgements.
- References.
Introduction: code smells and refactoring.
Refactoring is a practice that allows us to sustainably evolve code. To refactor problematic code, we first need to be able to recognize it.
Code smells are descriptions of signals or symptoms that warn us of possible design problems. It’s crucial to detect these problems and remove them as soon as possible.
Refactoring is cheaper and produces better results when done regularly. The longer a problematic piece of code lives, the more it takes to refactor it, and the biggest friction it will add to evolve new features directly contributing to accruing technical debt. Sustaining this situation over a long period of time may have a very negative economic impact. In the worst case scenario, the code might get too complicated to keep on maintaining it.
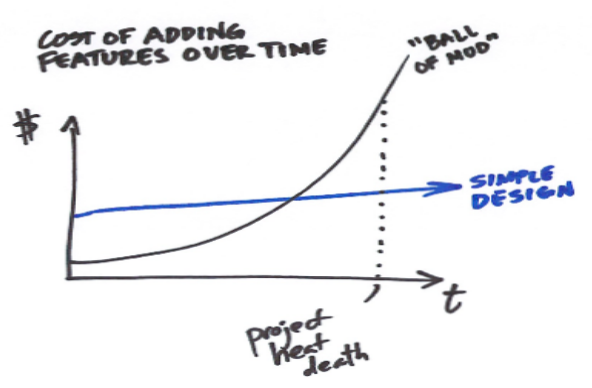
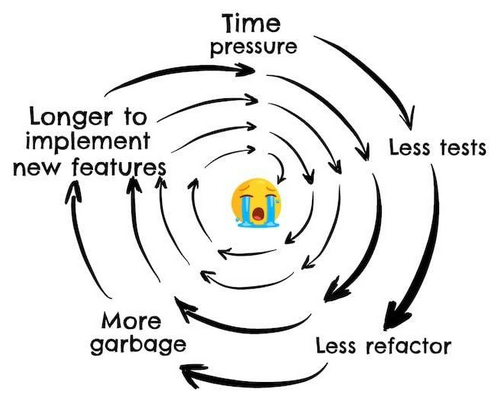
Another, sometimes not so visible, consequence of bad software quality is its effects on developers. Less refactoring, can lead to a less maintainable code that can lead to longer times to develop new features, which, in turn, means more time pressure to deliver, which can lead us to test less, which will allow us to refactor less… This vicious circle might have a very demoralising effect.
Understanding and being able to identify code smells gives us the opportunity of detecting design problems when they are still small and located in specific areas of our code, and, as such, are still easy to fix. This might have a very positive economic and emotional effect.
The problem is that code smells are not usually very well understood. This problem is understandable because code smells descriptions are sometimes abstract, diffuse and open to interpretation. Some code smells seem obvious, others not so much, and some might mask other smells.
Besides, we should remember that smells are only symptoms of possible design problems, not guarantees of the existence of problems. To further complicate matters, in addition to possible false positives, there are degrees to the problem that each smell represents, trade-offs between different smells and contraindications in their refactorings (sometimes “the cure is worse than the disease”).
Therefore, recognizing design problems through code smells is a subtle skill that requires experience and judgement. Acquiring this skill, which sometimes may feel like a kind of spider-sense, can take some time.
In our experience teaching and coaching teams, not being able to identify code smells is one of the greatest barriers to refactoring. Many developers do not detect design problems while they are still small and localised. What we often observe is that they don’t sense the design problems until the problems are quite large and/or have compounded with other problems, spreading through their codebase.
Code smells catalogues.
In 1999 Fowler and Beck published a code smells catalogue in a chapter of the book, Refactoring: Improving the Design of Existing Code. This catalogue contains the descriptions of 22 code smells.
In 2018 Fowler published a second edition of his book. In this new edition there are a number of changes with respect to the first, mainly in the code smells catalogue of smells and the refactorings catalogue (detailed in Changes for the 2nd Edition of Refactoring).
If we focus on the smells, which is the goal of this post, the changes are as follows:
- Four new code smells are introduced: Mysterious Name, Global Data, Mutable Data and Loops.
- Two code smells are removed: Parallel Inheritance Hierarchies and Incomplete Library Class.
- And four code smells are renamed: Lazy Class becomes Lazy Element, Long Method becomes Long Function, Inappropriate Intimacy becomes Insider Trading, and Switch Statement becomes Repeated Switches.
There are 24 code smells in total. Even though they usually have catchy and memorable names, it’s difficult to remember such a long list.
How could we better understand code smells? How could we remember them more easily?
In this post, and some later ones, we will talk about strategies to better understand and remember code smells.
Organisational strategies.
Organising and manipulating information, seeing it from different points of view, can help us understand and remember it better. Taxonomies are a type of organisational strategy that allows us to group study material according to its meaning. This helps to create significant groupings of information or “chunks” that will facilitate learning.
As we mentioned, the 2018 Fowler catalogue is a flat list that does not provide any type of classification. Although, reading the descriptions of the code smells, and the motivation sections of the different refactorings, we can glimpse that some smells are more related to each other than to other smells, these relationships are not expressed explicitly and remain blurred and dispersed in different parts of the book.
The use of taxonomies to classify similar code smells can be beneficial to better understand and remember code smells, and recognize the relationships that exist between them.
Taxonomies.
There have been different attempts to classify code smells according to different criteria. The most popular classification is that of Mäntylä et al 2006 but it is not the first one. Below we will show some taxonomies that we consider quite interesting.
Wake 2003.
Wake in his book, Refactoring Workbook, describes 9 new code smells that did not appear in Fowler’s original catalogue: Dead Code, Null Check, Special Case, Magic Number, Combinatorial Explosion, Complicated Boolean Expression, and three related to bad names: Type Embedded in Name, Uncommunicative Names and Inconsistent Names.
Wake explicitly classifies code smells by first dividing them into two broad categories, Smells within Classes and Smells Between Classes, depending, respectively, on whether the code smell can be observed from within a class or whether a broader context needs to be considered (various classes). Each of these categories is divided into subcategories that group code smells based on where they can be detected. This classification criterion, later called “occurrence” by Jerzyk, answers the question: “where does this code smell appear?”.
Following this “occurrence” criterion Wake finds 10 subcategories.
Within the category of Smells within Classes we find the following subcategories:
- Measured Smells: code smells that can be easily identified with simple length metrics.
- Names: code smells that create semantic confusion and affect our ability to create mental models that help us understand, remember, and reason about code.
- Unnecessary Complexity: code smells related to unnecessary code that adds mental load and complexity. Dead code, YAGNI violations, and accidental complexity.
- Duplication: developer’s nemesis. These code smells generate more code to maintain (cognitive and physical load), increase error proneness, and make it difficult to understand the code.
- Conditional Logic Smells: code smells that complicate conditional logic making it difficult to reason about and change, and increasing error proneness. Some of them are weak substitutes for object-oriented mechanisms.
The subcategories within the Smells between Classes category are:
- Data: code smells in which we find either pseudo objects (data structures without behaviour), or we find that some missing abstraction is missing.
- Inheritance: code smells related to misuse of inheritance.
- Responsibility: code smells related to a bad assignment of responsibilities.
- Accommodating Change: code smells that manifest when we encounter a lot of friction when introducing changes. They are usually caused by combinations of other code smells.
- Library Classes: code smells related to the use of third-party libraries.
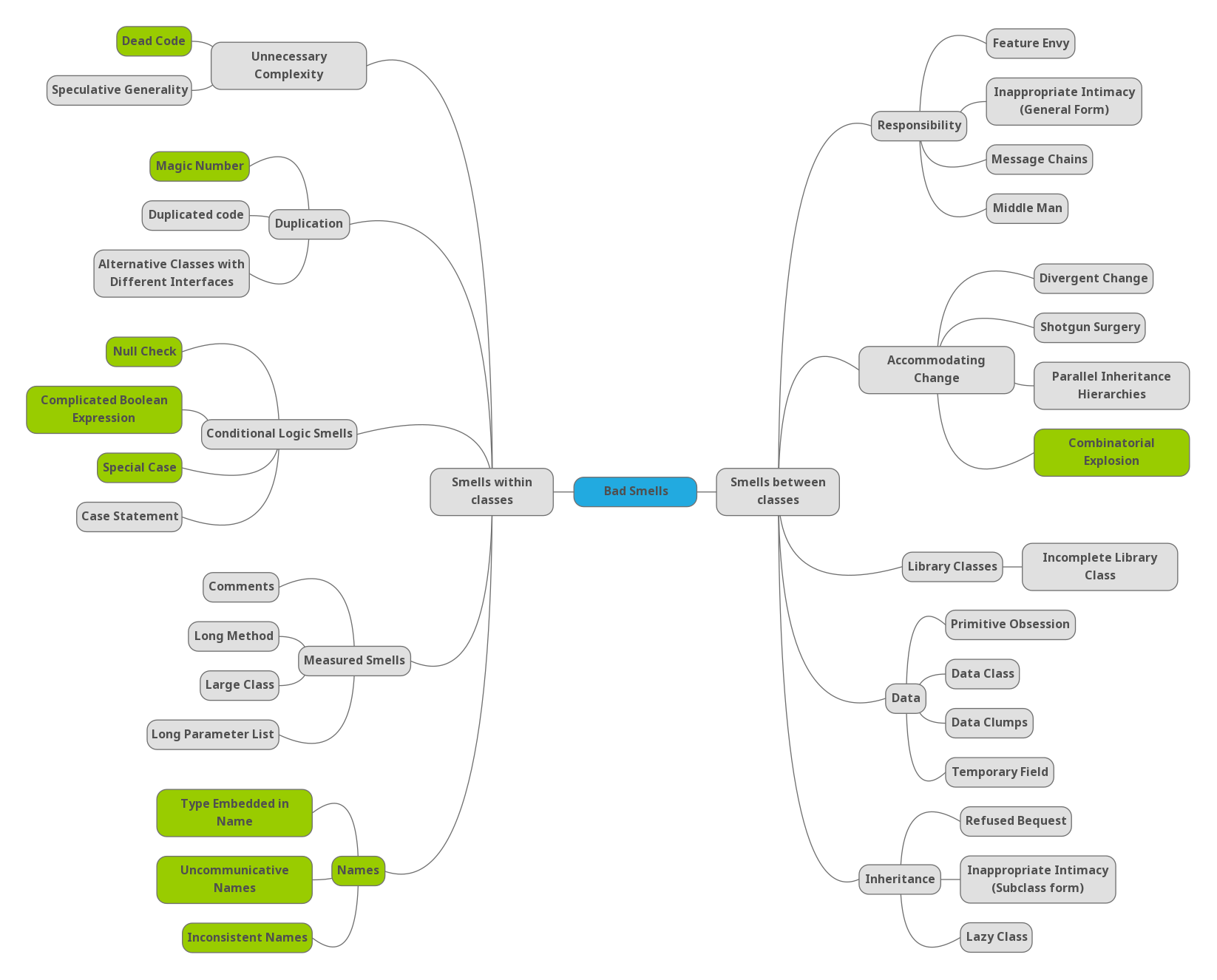
Wake presents each smell in a standard format with the following sections: Smell (the name and aliases), Symptoms (clues that may help detect it), Causes (notes on how it may have generated), What To Do (possible refactorings), Benefits (how the code will improve by removing it) and Contraindications (false positives and trade-offs). In some cases, he adds notes relating the code smell to design principles that might have helped to avoid it.
The book also contains many practical exercises and very useful tables (symptoms vs. code smells, smells vs. refactorings, reverse refactorings, etc.) and exercises that relate code smells to other concepts such as design principles or design patterns.
We highly recommend reading this book to delve into the discipline of refactoring and better understand when and why to apply the refactorings that appear in Fowler’s catalogue.
Although we also refer to to the rest of the taxonomies that we talk about in this post, the content about code smells in our course Code Smells & Refactoring is mainly based on Wake’s taxonomy seasoned with a bit of our own experience.
Mäntylä et al 2003.
In this taxonomy, code smells are grouped according to the effect they have on code (the type of problem, what they make difficult or the practices or principles that they break). This classification criteria is called “obstruction” by Jerzyk 2022.
The original classification from 2003 (A Taxonomy and an Initial Empirical Study of Bad Smells in Code) is comprised of 7 code smells categories: Bloaters, Object -Orientation Abusers, Change Preventers, Dispensables, Encapsulators, Couplers and Others.
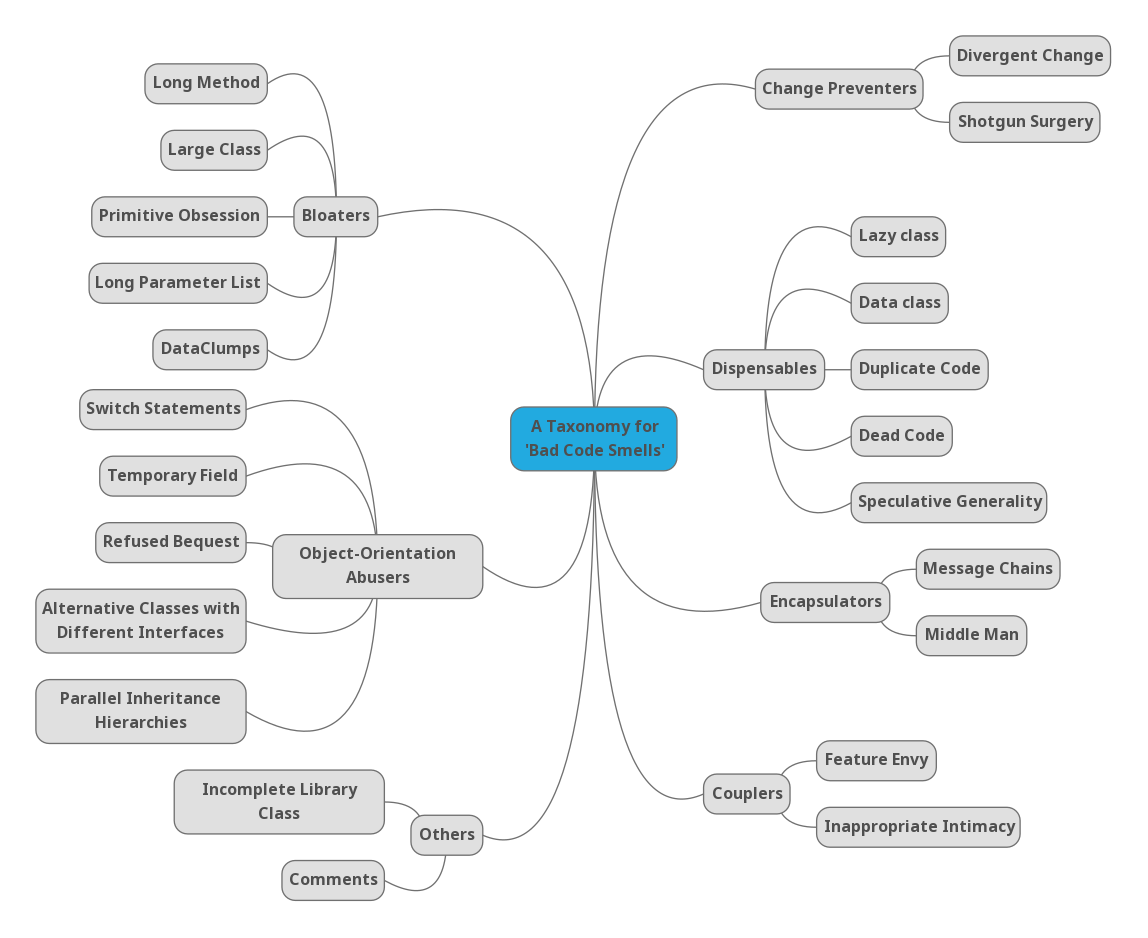
This is how they define each of the categories:
-
Bloaters: this category of smells represents something in the code that has grown so large that it can no longer be handled effectively.
-
Object-Orientation Abusers: this category of smells relates to cases where the solution does not fully exploit the potential of object-oriented design.
-
Change Preventers: this category refers to code structures that make it very difficult to change the code.
-
Dispensable: these smells represent something unnecessary that should be removed from the code.
-
Encapsulators: this category has to do with communication mechanisms or data encapsulation.
-
Couplers: these smells represent cases of tight coupling, which goes against object-oriented design principles
-
Others: this category contains the remaining code smells (Comments and Incomplete Library Class) that did not fit into any of the previous categories.
In their paper, Mäntylä et al discuss the reasons why each code smell is in a given category and not another, although they admit that some of them could be classified in more than one category.
Mäntylä et al 2006.
In 2006 Mäntylä et al published another paper (Subjective evaluation of software evolvability using code smells: An empirical study) in which they revised their original classification from 2003.
In this new version, they eliminated the Encapsulators (moving the Message Chains and Middle Man smells to the Couplers category) and Others (Comments and Incomplete Library Class disappear from the taxonomy) categories, and moved the Parallel Inheritance Hierarchies code smell from the Object-Orientation Abusers category to the Change Preventers category.
This version of their taxonomy is the one that has become most popular on the internet (it can be found on many websites, courses and posts), probably due to the greater accessibility (readability) of the summary of the paper that appears on the web: A Taxonomy for “Bad Code Smells”.
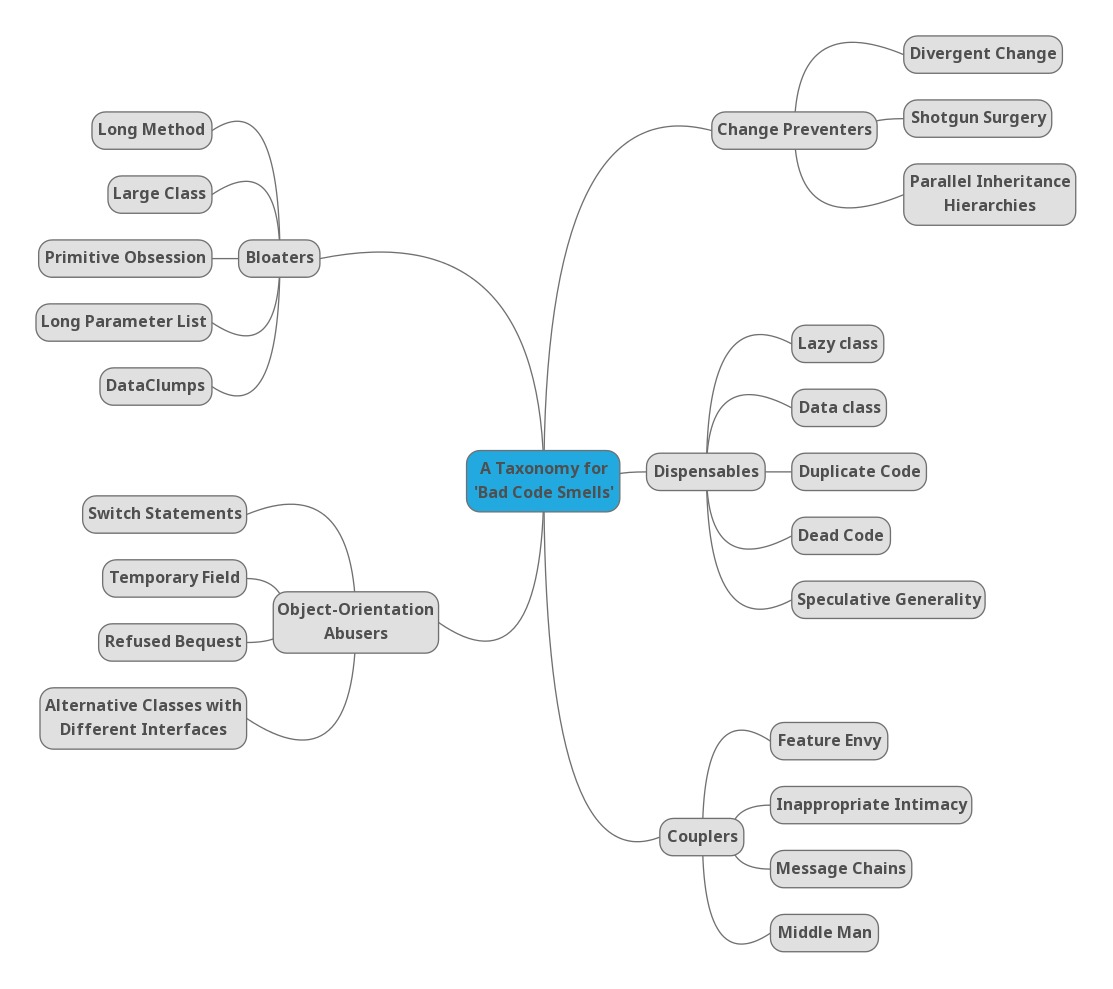
What is interesting is not so much the discussion of which category each smell should fall into, but rather to start thinking that a given smell can have different types of effects on the code and the relationships between these effects. In fact, subsequent classifications from the point of view of the effect of a smell on the code (“obstruction”) consider it more useful not to lose the information that a code smell can produce several effects. This leads to no longer considering categories as exclusive, which makes it possible that the same smell can fall into several categories.
Jerzyk et al 2022.
In 2022 Marcel Jerzyk published his master’s thesis, Code Smells: A Comprehensive Online Catalog and Taxonomy and a paper with the same title. His research on code smells had three goals:
-
Providing a public catalogue that could be useful as a unified knowledge base for both researchers and developers.
-
Identifying all the possible concepts that are being characterised as code smells and determining possible controversies about them.
-
Assigning appropriate properties to code smells in order to characterise them.
To achieve these objectives, they carried out a review of the existing literature on code smells up to that moment, with special emphasis on code smell taxonomies.
In the thesis 56 code smells are identified and described, of which 16 are new original proposals (remember that Wake described 31 code smells and Fowler 24 in his last review).
Descriptions and discussions of each of these 56 code smells can be found in Jerzyk’s master’s thesis.
Analysing the classification criteria of the taxonomies proposed up to that moment, Jerzyk finds three significant criteria to categorise code smells:
- Obstruction: this is the criterion used by Mäntylä et al to classify smells in their taxonomy, it’s also the most popular criterion. It informs us about the type of problem that a code smell causes in the code (what they make difficult or the practices or principles that they break). In the thesis they update the Mäntylä taxonomy, adding three new groups: Data Dealers, Functional Abusers and Lexical Abusers. Below we present a mental map that shows the classification of the 56 code smells according to only this criterion.
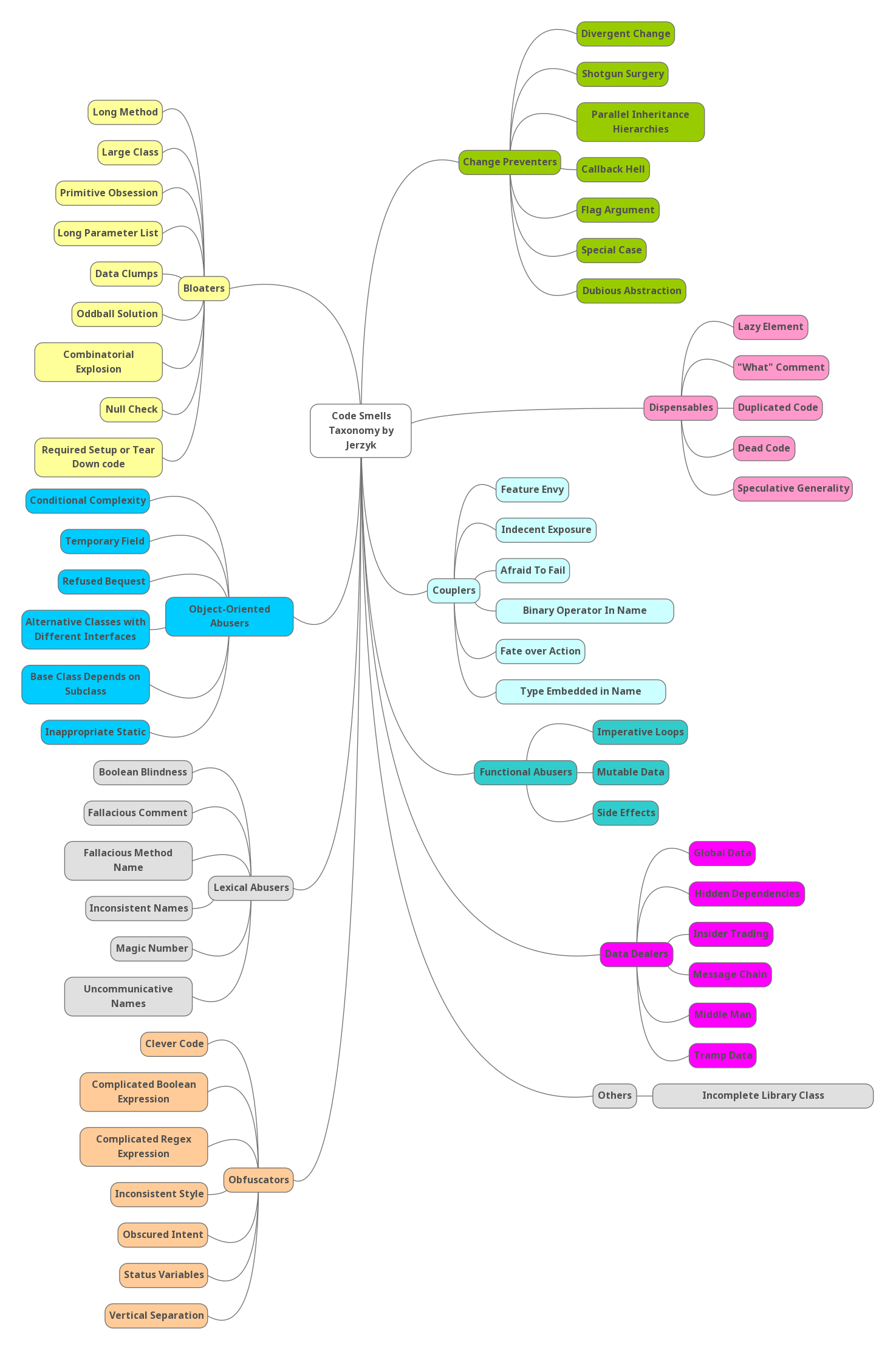
-
Expanse: inspired by Wake’s taxonomy, this criterion talks about whether the code smell can be observed in a reduced context (within a class) or if a broader context (between several classes) needs to be considered. Possible categories are Within Class and Between Classes.
-
Occurrence: Also inspired by Wake’s taxonomy, this criterion is related to the location where (or the method by which) a code smell can be detected. Possible categories are Names, Conditional Logic, Message Calls, Unnecessary Complexity, Responsibility, Interfaces, Data, Duplication and Measured Smells.
The following table shows the 56 code smells in Jerzyk’s thesis classified according to the three criteria discussed above:
| Code Smell | Obstruction | Expanse | Occurrence |
|---|---|---|---|
| Long Method | Bloaters | Within | Measured Smells |
| Large Class | Bloaters | Within | Measured Smells |
| Long Parameter List | Bloaters | Within | Measured Smells |
| Primitive Obsession | Bloaters | Between | Data |
| Data Clumps | Bloaters | Between | Data |
| Null Check | Bloaters | Between | Conditional Logic |
| Oddball Solution | Bloaters | Between | Duplication |
| Required Setup/Teardown | Bloaters | Between | Responsibility |
| Combinatorial Explosion | Bloaters | Within | Responsibility |
| Parallel Inheritance Hierarchies | Change Preventers | Between | Responsibility |
| Divergent Change | Change Preventers | Between | Responsibility |
| Shotgun Surgery | Change Preventers | Between | Responsibility |
| Flag Argument | Change Preventers | Within | Conditional Logic |
| Callback Hell | Change Preventers | Within | Conditional Logic |
| Dubious Abstraction | Change Preventers | Within | Responsibility |
| Special Case | Change Preventers | Within | Conditional Logic |
| Feature Envy | Couplers | Between | Responsibility |
| Type Embedded In Name | Couplers | Within | Names |
| Indecent Exposure | Couplers | Within | Data |
| Fate over Action | Couplers | Between | Responsibility |
| Afraid to Fail | Couplers | Within | Responsibility |
| Binary Operator in Name | Couplers | Within | Names |
| Tramp Data | Data Dealers | Between | Data |
| Hidden Dependencies | Data Dealers | Between | Data |
| Global Data | Data Dealers | Between | Data |
| Message Chain | Data Dealers | Between | Message Calls |
| Middle Man | Data Dealers | Between | Message Calls |
| Insider Trading | Data Dealers | Between | Responsibility |
| Lazy Element | Dispensables | Between | Unnecessary Complexity |
| Speculative Generality | Dispensables | Within | Unnecessary Complexity |
| Dead Code | Dispensables | Within | Unnecessary Complexity |
| Duplicate Code | Dispensables | Within | Duplication |
| “What” Comments | Dispensables | Within | Unnecessary Complexity |
| Mutable Data | Functional Abusers | Between | Data |
| Imperative Loops | Functional Abusers | Within | Unnecessary Complexity |
| Side Effects | Functional Abusers | Within | Responsibility |
| Uncommunicative Name | Lexical Abusers | Within | Names |
| Magic Number | Lexical Abusers | Within | Names |
| Inconsistent Names | Lexical Abusers | Within | Names |
| Boolean Blindness | Lexical Abusers | Within | Names |
| Fallacious Comment | Lexical Abusers | Within | Names |
| Fallacious Method Name | Lexical Abusers | Within | Names |
| Complicated Boolean Expressions | Obfuscators | Within | Conditional Logic |
| Obscured Intent | Obfuscators | Between | Unnecessary Complexity |
| Vertical Separation | Obfuscators | Within | Measured Smells |
| Complicated Regex Expression | Obfuscators | Within | Names |
| Inconsistent Style | Obfuscators | Between | Unnecessary Complexity |
| Status Variable | Obfuscators | Within | Unnecessary Complexity |
| Clever Code | Obfuscators | Within | Unnecessary Complexity |
| Temporary Fields | O-O Abusers | Within | Data |
| Conditional Complexity | O-O Abusers | Within | Conditional Logic |
| Refused Bequest | O-O Abusers | Between | Interfaces |
| Alternative Classes with Different Interfaces | O-O Abusers | Between | Duplication |
| Inappropriate Static | O-O Abusers | Between | Interfaces |
| Base Class Depends on Subclass | O-O Abusers | Between | Interfaces |
| Incomplete Library Class | Other | Between | Interfaces |
Some of the names in the table are different from those that usually appear in the literature. The changes in naming were due to the introduction of more updated names, as is the case for, for instance, Lazy Element or Insider Trading which were previously called Lazy Class and Inappropriate Intimacy, respectively.
Several smells are new:
- Some, like Afraid to Fail, Binary Operator in Name, Clever Code, Inconsistent Style, and Status Variable, are completely new ideas.
- Others are concepts that already existed in the literature but had not been considered in the context of code smells before: Boolean Blindness or Callback Hell.
- Three of them propose alternatives for code smells that are being questioned in the literature: “What” Comment as an alternative to Comments, Fate over Action as an alternative to Data Class, and Imperative Loops as an alternative to Loops (see Jerzyk’s thesis for more on why these original code smells are debatable).
- Others generalise problematic concepts that have arisen in the literature: Complicated Regex Expression, Dubious Abstraction, Fallacious Comment, Fallacious Method Name.
- Finally, a known problem (especially in the field of functional programming), which had not been considered as a code smell until now: Side Effects.
One super useful and practical thing for developers in Jerzyk’s work is an online code smells catalogue that, when published, included the 56 code smells in the thesis. This catalogue is an accessible and searchable website. On the date of publication of this post, the catalogue contains 56 code smells.
In the catalogue code smells can be filtered by different classification criteria.
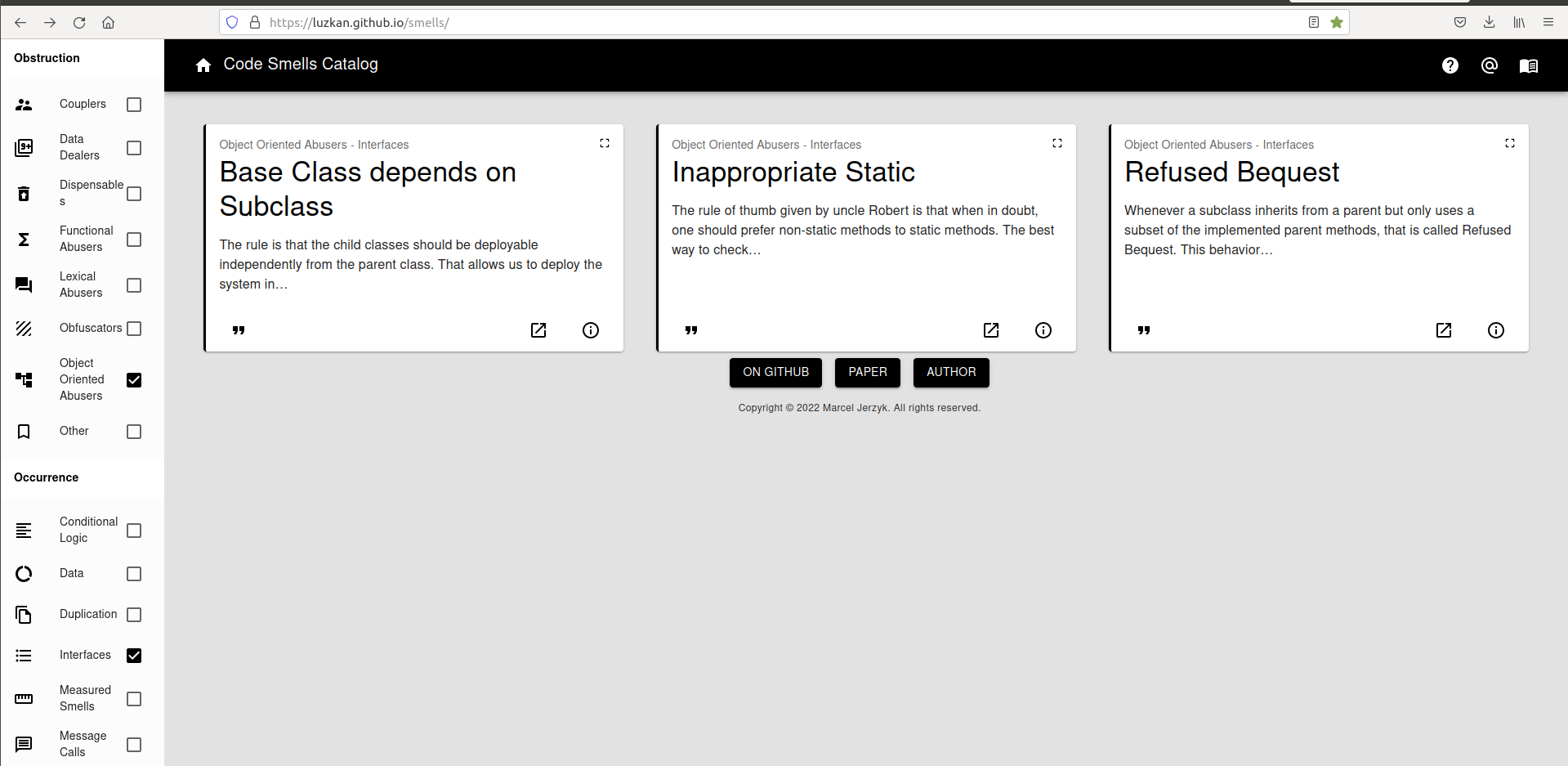
For example, the screenshot above shows the result of filtering code smells that are OO Abusers and affect Interfaces which includes the Refused Bequest, Base Class depends on Subclass, and Inappropriate Static code smells.
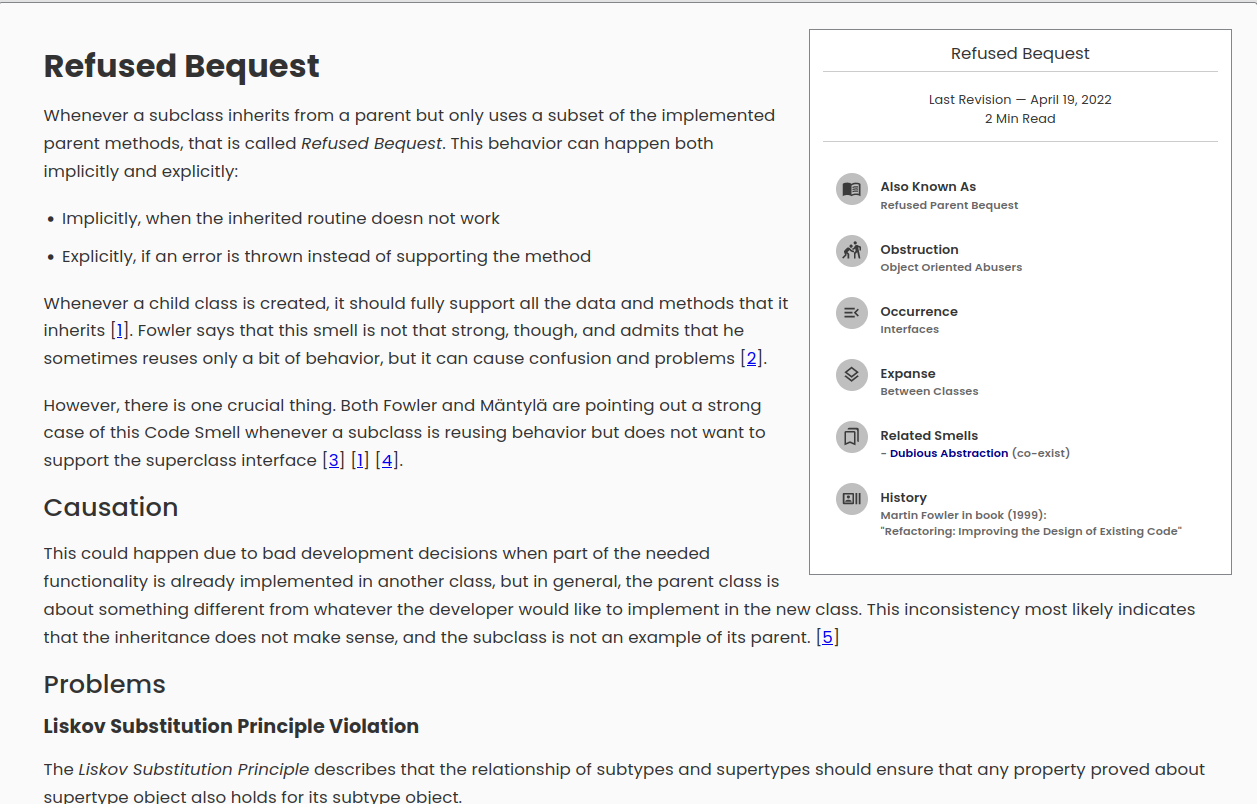
For each code smell, the catalogue presents the following sections: Smell (discussion of the smell), Causation (possible causes of the code smell), Problems (problems that the smell can cause or design principles violates), Example (examples of minimal code that illustrate the possible symptoms of a code smell and show a possible solution), Refactoring (possible refactorings) and Sources (articles or books that have described this code smell). It also includes a box containing information about possible aliases of the code smell, the category to which it belongs according to the criteria of obstruction, occurrence and expanse, the related smells and its relationship to them, and the historical origin of the code smell.
Conclusions.
Since the code smell concept was coined in 1999, many new smells have appeared. Catalogues as flat lists of code smells catalogue are hard to remember, and don’t help to highlight the relationships that exist between different code smells.
We have presented several code smells taxonomies that can help us see code smells from different points of view and relate them to each other according to different criteria: the problems they cause in the code, where they can be detected or the context that needs to be taken into account to detect them.
These meaningful groupings of code smells will help us understand and remember them better than flat catalogue lists.
Finally we’d like to highlight the recent work by Marcel Jerzyk which has not only proposed new smells and created a new multi-criteria taxonomy, but also has made available to us an online code smells catalogue in the form of an open-source repository and accessible and searchable website, which we believe can be very useful. useful and practical for both researchers and developers. I encourage you to take a look.
Acknowledgements.
I would like to thank my colleagues Fran Reyes, Antonio de La Torre, Miguel Viera and Alfredo Casado for reading the final drafts of this post and giving me feedback.
I’d also like to thank nikita for her photo.
References.
Books.
- Refactoring: Improving the Design of Existing Code 1st edition 1999, Martin Fowler et al.
- Refactoring: Improving the Design of Existing Code 2nd edition 2018, Martin Fowler et al.
- Refactoring Workbook, William C. Wake
- Refactoring to Patterns, Joshua Kerievsky
- Five Lines of Code: How and when to refactor, Christian Clausen
- The Programmer’s Brain, Felienne Hermans
Papers.
- A Taxonomy and an Initial Empirical Study of Bad Smells in Code, Mantyla et al, 2003.
- Subjective evaluation of software evolvability using code smells: An empirical study, Mantyla et al, 2006.
- A Taxonomy for “Bad Code Smells” , Mantyla et al, 2006.
- Code Smells: A Comprehensive Online Catalog and Taxonomy, Marcel Jerzyk, 2022.
- Code Smells: A Comprehensive Online Catalog and Taxonomy Msc. Thesis, Marcel Jerzyk, 2022.
- Extending a Taxonomy of Bad Code Smells with Metrics, R. Marticorena et al, 2006
Photo by nikita in Pexels.