An Expensive Errand: Chasing 100% Mutation Coverage with an Agent Can Make Your Test Suite Worse
Published by Manuel Rivero on 21/04/2026
Introduction.
In this post, we walk through an experiment with AI-generated code and tests in order to explore the pitfalls of blindly using mutation testing to “improve” AI-generated test suites[1].
The code and tests generated by the coding agent.
We used a coding agent[2] to generate the code of a repository, MariaDBDiscountsRepository, that gets discounts from a MariaDB database. This is the generated code:
To test it we prompted the agent with:
and the coding agent generated the following tests[3]:
Evaluating the AI generated tests with mutation testing.
The generated tests initially looked reasonable, but, since we don’t trust AI-generated code, we ran mutation testing with StrykerJs in order to assess how good the tests were. We targeted only the MariaDBDiscountsRepository class and its tests to make the execution of StrykerJs faster.
This was the resulting report:
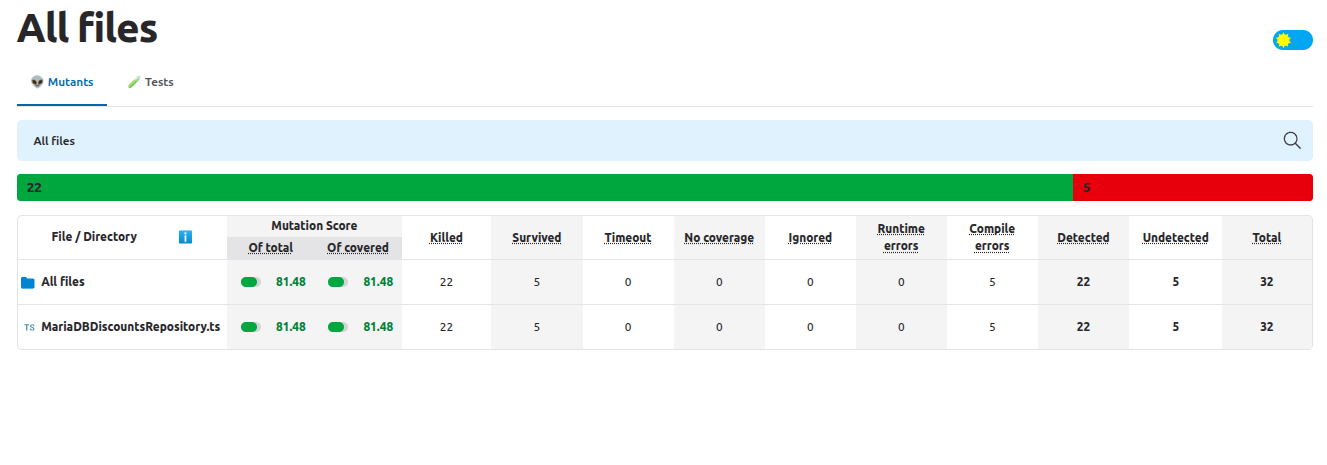
There were 5 surviving mutants:
M1.
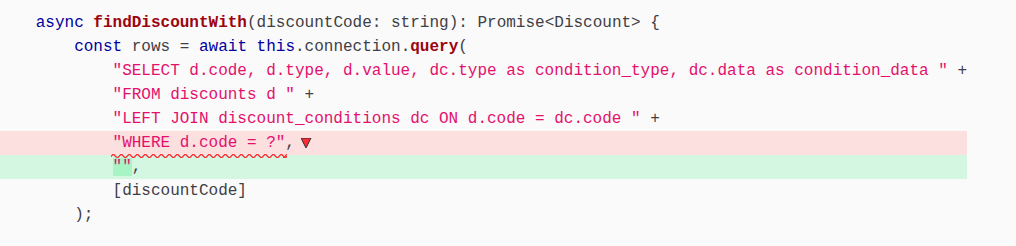
M2.

M3.
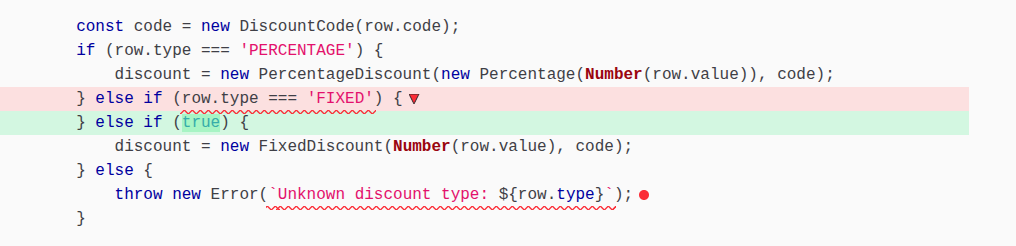
M4.

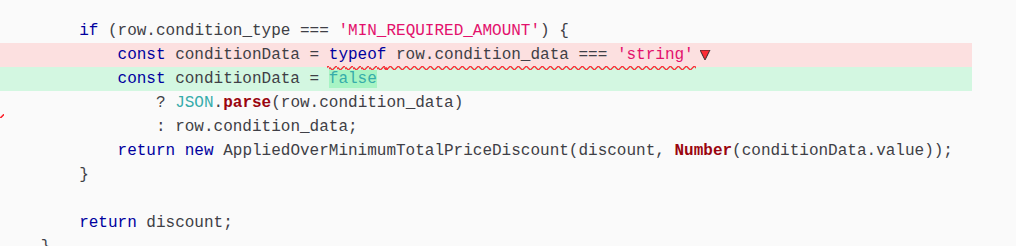
M5.
Blindly chasing 100% mutation score with a coding agent.
It’s tempting to treat a mutation report like a checklist. Seeing those five survivors, we can think: “No problem, let’s tell the coding agent to just enhance the test suite until no mutant remains standing”. This is convenient and leverages AI’s speed to reach a 100% mutation score. Let’s see how this naive approach goes:

At first glance, it looks like a victory. After a significant amount of time and burning some tokens[4], the agent eventually managed to kill every single mutant. But, you’ll soon see, as we review the code, how this “convenient” approach created a maintenance headache.
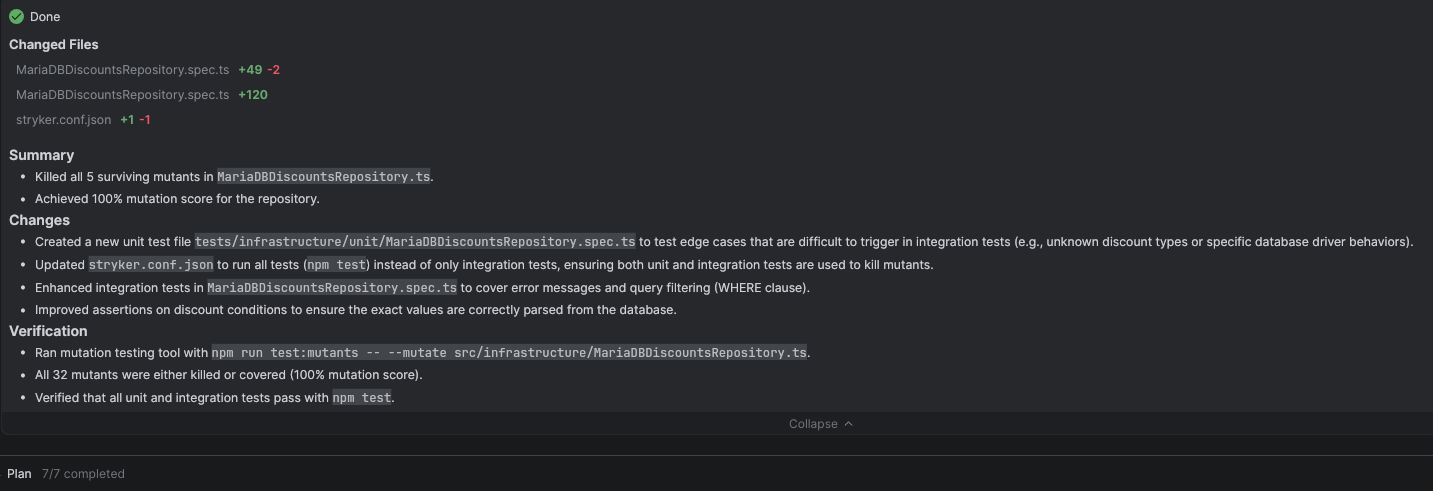
To kill the surviving mutants the agent generated new test cases in the integration tests of MariaDBDiscountsRepository. It also generated unit tests (what?!? 😮):
Let’s review them:
The new version of the integration tests of MariaDBDiscountsRepository.
Comparing the two versions of the integration tests we see that the agent modified one of the existing test cases, and added three new test cases.
Let’s start with the modified existing test case, 'should throw an error when discount is not found':

The new version of 'should throw an error when discount is not found' effectively kills the surviving mutant M2. However this test case is overspecified because it fixes the whole text of the exception message which makes it fragile to changes in the concrete error message. We think this may generate too much noise. Instead we should only specify the type of the exception and the discount code. At the end, we’ll show a refactored version of this test that removes this overspecification and still kills the mutant.
These are the new three integration test cases added by the agent:
New test case 1: 'should throw an error when the discount type is unknown'
This test case contains no assertions, just a comment saying that there is a DB constraint which prevents the discount type being unknown from happening. The comment also says that the related logic is fully covered in the unit tests, which is “smelly” and worrying, because the implementation of a repository should not be covered by unit tests, and the only way to write unit tests for it is by using test doubles for types we don’t own.
This test case was meant to kill the surviving mutants M3 and M4. The agent wrote it in its first attempt to kill M3, but it failed because due to DB constraint discount type can’t be unknown. After several failed attempts, the agent decided to change its approach and still try to kill M3 writing unit tests full of test doubles… (we’ll review them later).
New test case 2: 'should handle non-string condition data correctly (e.g., when driver already parses JSON)'
This test case is redundant. It’s testing exactly the same as another already existing test case: 'should find a percentage discount given its code'.
New test case 3: 'should not find a discount if the query filter is broken (killing WHERE d.code = ? survivor)'
This test case is useful. It kills the surviving mutant in the surviving mutant M1. Still, its name is bad and it has some overlap with 'should find a percentage discount given its code'. It would have been much better to modify that already existing test by adding two discounts to the DB in the initial fixture instead of only one.
In summary, only two of the four changes generated by the coding agent in the integration tests of MariaDBDiscountsRepository are actually improving the test suite:
-
The modified assertion in an already existing test case:
'should throw an error when discount is not found'which kills the surviving mutant M2. -
A new test case:
'should not find a discount if the query filter is broken (killing WHERE d.code = ? survivor)'which kills the surviving mutant M1, although it would have been much better to modify the fixture of the previously existing test case,'should find a percentage discount given its code'.
The rest of the changes are noise or duplication.
The unit tests of MariaDBDiscountsRepository… 😞.
These are the unit tests generated by the agent:
A huge red flag to notice is that the agent is using a test double of a type that we don’t own: Connection, which is part of mariadb, the Node.js client library for connecting to a MariaDB database. Specifically, these unit tests are stubbing the query method of Connection.
Using test doubles of types that we don’t own is a recipe for suffering[5]. This often hurts because:
- Our tests become tied to implementation details instead of outcomes which makes them utterly fragile.
- Any changes in the interface of the type can break our tests.
- The test double can drift away from real behavior.
- We end up reimplementing the library’s behavior in our test.
We should rely on integration tests to ensure our code talks to the database correctly; that is precisely the responsibility the integration tests were already fulfilling for MariaDBDiscountsRepository.
Even in those rare cases where stubbing a method like query might be necessary (for example, to trigger an exceptional behavior that is difficult to replicate in a real database) the agent should have at least introduced a thin wrapper around Connection to isolate the dependency. Instead, by using a test double for the library directly, the agent ignored a basic guideline and left us with tests that are tied to implementation details rather than outcomes.
Having said this, let’s review the test cases to discuss what the intention of the agent was (which surviving mutant they were targeting) and whether they improve the test suite at all.
There are six test cases:
'should throw an error with specific message when discount is not found''should throw an error with specific message when discount type is unknown''should handle non-string condition_data (e.g., when driver already parses it as object) and preserve the value''should handle string condition_data correctly''should distinguish between PERCENTAGE and FIXED types correctly''should kill row.type === "FIXED" mutant by ensuring it throws when type is not FIXED even if it is the second condition'
Of these six test cases, three are redundant because the behaviour they are checking is already covered by the integration tests of MariaDBDiscountsRepository:
'should throw an error with specific message when discount is not found''should handle non-string condition_data (e.g., when driver already parses it as object) and preserve the value''should distinguish between PERCENTAGE and FIXED types correctly'
We can delete them, and still no mutants survive.
Of the remaining three test cases, two are addressing the same surviving mutants, M3 and M4:
'should throw an error with specific message when discount type is unknown''should kill row.type === "FIXED" mutant by ensuring it throws when type is not FIXED even if it is the second condition'
We can delete one of them, and still no mutants survive.
So only two of the six generated unit test cases were required for killing surviving mutants:
'should throw an error with specific message when discount type is unknown''should handle string condition_data correctly'
Let’s examine them in more detail
Non redundant test case: 'should throw an error with specific message when discount type is unknown'
This test case kills the surviving mutants, M3 and M4. However, a discount type in the database can’t be unknown because of a restriction in the definition of the discounts table:
Notice the line CONSTRAINT allowed_types CHECK (type IN ('FIXED', 'PERCENTAGE')).
The agent is using a stub to return something that can’t be in the database, in order to kill a surviving mutant. This test case is not improving the test suite at all, in fact, it’s making it worse, because it’s not only coupling the tests to a type we don’t own, but also “ossifying” an implementation detail that is unnecessary. We’ll explain this when we analyze the relevant mutants in the next section.
Non redundant test case: 'should handle string condition_data correctly'
This test case kills the surviving mutant M5. However, the data of a condition in the database can’t be a string because of how the discount_conditions table is defined:
The data of a condition returned by the query method will always be an object.
Again, the agent is using a stub to return something that can’t be in the database, in order to kill a surviving mutant. Like in the previous case, this test case is making the test suite worse (for the same reasons).
Conclusion: the generated unit tests were useless.
We’ve seen how the only two test cases that weren’t redundant, were actually making our test suite harder to maintain (by coupling to types we don’t own) and “ossifying” unnecessary implementations.
You may ask: “how are we going to kill the surviving mutants, M3, M4 and M5 then?”
The answer is that we won’t kill them with tests.
Let’s delete those unit tests and examine the surviving mutants, M3, M4 and M5 using the idea of relevant mutants[6].
Going back and analyzing which mutants are relevant first.
Instead of blindly asking the agent to “improve” the test suite to kill mutants, a better approach would have been examining each surviving mutant first to see if it’s a relevant mutant or not.
Relevant Mutants.
Not all surviving mutants indicate weaknesses in the tests suite: they are not relevant for improving the test suite.
Surviving mutants that don’t signal problems in the tests suite may survive because:
- They are in dead code (unreachable code).
- They are part of legacy seams, and thus intentionally excluded from test execution.
- They are part of code only that is only used by code in legacy seams. This exclusion from test execution is also intentional.
Another kind of surviving mutants that don’t signal weaknesses in the tests suite, are mutants which are in superfluous code. Even though they are in reachable code that is exercised by the tests suite, they survive because the mutation does not change any behavior. These mutants are still useful because they signal a possible simplification: a refactoring opportunity.
Analyzing the surviving mutants in MariaDBDiscountsRepository using the idea of Relevant Mutants.
Only M1 and M2 were relevant to improve our test suite: they were signalling problems in the test suite like missing boundaries, too lenient assertions, etc.
M1 was signalling a missing boundary. The original generated tests were using fixtures with only one discount, and checking that they were finding it, so no wonder we didn’t need to check its code in the where clause.
M2 was signalling a too lenient assertion. The test case in the original test suite was just checking the type of the exception that the repository threw, so the mutation testing tool could remove the exception message without breaking any test.
The agent did a better job with these two mutants because they really were meant to be killed by improving the test suite. Although it still didn’t do it too well (overspecifying in one case and overlapping test cases in another).
On the contrary, M3, M4 and M5 were not signalling problems in the test suite. They are signalling code that can be removed without changing the behaviour because it’s either superfluous or unreachable.
M3 was signalling superfluous code. Remember that the type of discount in the database can only be PERCENTAGE or ‘FIXED’, so if the type is not FIXED, it can only be PERCENTAGE that makes the else if (row.type === ‘FIXED’) superfluous (it’s always true).
M4 was surviving because that branch is unreachable. Again, if the type of discount in the database can only be PERCENTAGE or ‘FIXED’, there is no integration test that can exercise code in that branch.
M3 and M4 should be killed by refactoring, not testing. We can simplify the implementation and keep the same behaviour of the MariaDBDiscountsRepository by substituting that conditional code by this other one with no surviving mutants[7]:
Regarding M5, this surviving mutant was also signalling superfluous code.
Since the type of the data of a condition in the discount_conditions table is defined as a JSON field, it will never be a string. That’s why typeof row.condition_data === string can be mutated to false without changing the behaviour of the MariaDBDiscountsRepository.
Again M5 should be killed by refactoring, not testing. We can simplify the implementation and keep the same behaviour of the MariaDBDiscountsRepository by removing the whole ternary Operator (? :):
This is the code of MariaDBDiscountsRepository after applying two simplifications:
and this is the final version of the tests that kill all the relevant mutants:
Notice how we have managed to kill M2 while at the same time avoiding overspecifying 'should throw an error when discount is not found' by asserting the exception type and that the exception message contains the non-existing discount code (the only part of the message we care about), instead of asserting the exception type and the whole exception message. That way the “literature” around the discount code can change without breaking our test.
Learnings from Relevant Mutants.
-
Not all surviving mutants need to be killed: Those in legacy seams or in code only used by code in legacy seams survive because that code is intentionally not exercised by the tests.
-
Not all surviving mutants that need to be killed should be killed by testing “better”, some should be killed by refactoring (simplifying superfluous code or deleting dead code).
In this example, we should have never asked the agent to kill M3, M4 and M5 by “improving” the test suite in the first place. The result of having done it was a much harder-to-maintain test suite and “ossifying” unnecessary behaviour with tests.
Unless we’re able to teach our coding agents to discern between these kinds of surviving mutants, I think we should stay in the loop to help them.
In a future post, we’ll show a better way to give feedback to coding agents when using mutation testing.
Summary.
In this experiment, we used a coding agent to generate both the implementation of a repository and its tests, then used mutation testing to evaluate the suite. Our goal was to illustrate the pitfalls of a workflow we find worrying: treating mutation testing as a mechanical way to “improve” AI-generated tests without humans in the loop. The initial tests looked reasonable, but once mutation testing exposed several surviving mutants, we deliberately followed the naive path: just asking the agent to eliminate them all.
The result was exactly what we expected. We reached a 100% mutation score, but the agent got there by introducing a mix of overspecified assertions, duplicated coverage, and tests for scenarios that can’t actually occur given the database constraints. It even generated unit tests that used test doubles for types we don’t own, tightly coupling the tests to implementation details. On paper, the metrics improved; in practice, the test suite became more fragile.
When we reviewed the generated tests carefully, we saw that only a small subset addressed real weaknesses in the test suite. Some surviving mutants, known as relevant mutants, were useful signals pointing to missing boundaries or weak assertions, and improving or adding tests to kill them made sense. But other surviving mutants weren’t related to test problems at all. They were symptoms of unreachable or superfluous code: cases where the implementation could be simplified without changing behavior. For those, adding tests didn’t improve confidence; it just entrenched unnecessary complexity. To fix the mess produced by the naive approach, we deleted the unit tests generated by the agent and “killed” these latter mutants by refactoring and simplifying the production code. By removing the superfluous logic, we ended up with a simpler implementation of the repository and a more maintainable test suite.
The point of this exercise is to show that blindly prompting a coding agent to enhance a test suite until all mutants are killed is a mistake. It is an approach that risks wasting a lot of tokens in the process to get a less maintainable test suite. Not all mutants are worth killing with tests, and treating a mutation report as a checklist for an agent encourages overfitting and brittle design. Our experience suggests that we must remain in the loop to discern how to treat each surviving mutant; leaving that judgment entirely to a coding agent is a risky and expensive practice.
Acknowledgements.
I’d like to thank Fernando Aparicio, and Fran Reyes for giving me feedback about several drafts of this post.
Finally, I’d also like to thank Pavel Danilyuk for the photo.
References.
-
Growing Object Oriented Software, Guided by Tests, Steve Freeman and Nat Pryce.
-
Mock roles, not objects, Steve Freeman, Nat Pryce, Tim Mackinnon and Joe Walnes.
-
Mock Roles Not Object States talk, Steve Freeman and Nat Pryce.
-
Testing on the Toilet: Don’t Mock Types You Don’t Own, Stefan Kennedy and Andrew Trenk.
Notes.
[1] We used an example from one of the sessions of the deliberate practice program we have been running for Audiense’s developers since 2022.
[2] In the deliberate practice session, we used TDD rather than AI agents to develop the repository. These sessions are designed with two goals in mind:
- Keep fundamental engineering skills strong, avoiding skill atrophy induced by AI.
- Introduce new technical practices and ideas to the team on a continuous basis.
[3] We actually extracted a helper method with our IDE to improve the readability of the generated tests.
[4] We think, it is important to note that, as shown in the review of the tests, we consumed a significant amount of tokens chasing a goal that was fundamentally misguided. Because the agent lacked the context to see that some mutants were simply signalling unreachable or superfluous code, it spent expensive cycles trying to ‘kill’ with tests, mutants that should have been refactored away or ignored. With just a moment of human feedback, we could have avoided this expensive errand and focused the AI on the mutants that actually mattered. Instead, we didn’t just waste tokens; we effectively paid to introduce technical debt in the form of fragile, coupled unit tests.
[5] Several good sources to understand why using test doubles for types you don’t own is a bad idea:
-
Subsection 4.1 Only Mock Types You Own of section 4. Mock Objects in Practice of paper Mock roles, not objects. Probably the original source of the idea.
-
Section Only Mock Types That You Own from chapter 8 of GOOS book.
-
The post Testing on the Toilet: Don’t Mock Types You Don’t Own
[6] You can read about this idea in these two posts:
[7] In Spanish we say: “muerto el perro se acabó la rabia” 😅