Refactoring the tests after a "Breaking Out" (peer detection techniques)
Published by Manuel Rivero on 10/11/2025
1. Introduction.
This post is a continuation of our previous post devoted to the breaking out technique, in which we explained the breaking out technique which consists in splitting a large object into a group of collaborating objects and/or values.
This technique is useful to fix cohesion problems caused by delaying design decisions until we learn more about the domain when facing volatile and poorly understood domains.
We also described how to use code smells and, in more severe cases, testability problems as indicators of poor cohesion to recognize when we need the technique, and how to apply it.
Finally, we highlighted two facts about the code after applying a breaking out:
- The new objects created through this refactoring are treated as internals rather than peers.
- The tests still have poor readability, writability, specificity and composability, but high structure-insensitivity.
At the end of the previous post, there were to open questions that we’ll try to answer in this post:
- Should we refactor the tests now or later?
- How do we refactor the tests?
- How do we decide if we should promote an internal object to be a peer?
2. Refactoring the tests now or later?
2. 1. Context.
The following figure summarizes the analysis of some test properties of the original tests we did in our previous post:
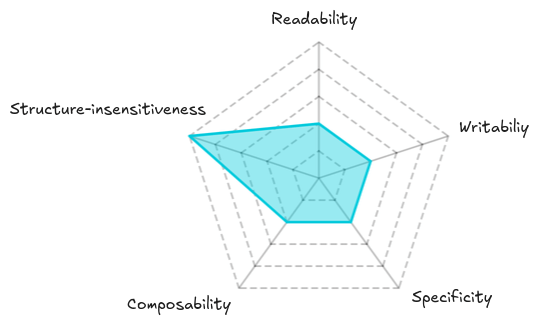
This analysis of test properties will help us identify the trade-offs involved in deciding whether to refactor the tests now or defer it to a more advantageous time.
Another information we need to consider to make the decision is how we got to this situation. Let’s do a quick recap:
-
We were starting a new area of code, and test-drove the behaviour through the public interface of an object without attempting to impose much structure, in order to have more time to learn before committing to any design decision.
-
After observing some code smells (and possibly some test smells) produced by a lack of cohesion, we decided to break up the original object into smaller components. After that refactoring, the resulting composite object (original object + extracted internals and values) has better cohesion, but the original tests have not changed.
We also need to know that the refactoring of the test comprises two steps:
-
Testing “problematic” internals and values independently, (where “problematic” means that they cause painful testability problems).
-
Refactoring the original tests.
Let’s analyze the first step.
2. 2. Testing “problematic” types independently now or later?
2. 2. 1. Consequences of testing “problematic” types independently.
Let’s start by thinking what testing an internal object or value independently means in terms of readability, writability, specificity, composability and structure-insensitivity.
Improvements in readability and writability.
The new tests would be more granular and focused because they are testing only one behaviour. This will make them easier to write and understand.
Improvement in specificity.
With these new tests, it would be much easier to interpret test failures (including failures in the original tests).
Improvement in composability.
We can separately test each different behaviour (dimension of variability) through its interface. Then adding a few test cases that verify the combination of behaviours will allow the number of test cases to grow additively instead of multiplicatively, while still providing confidence that the tests are sufficient.
Reduced structure-insensitivity.
The new tests are coupled to the interfaces of the new types. Since the original tests were not aware of these interfaces, this added coupling increases the cost of any refactoring that changes one of the new interfaces.
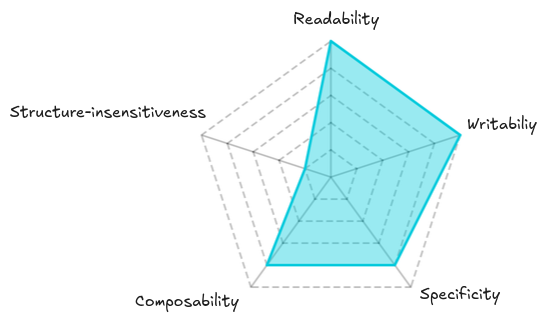
Therefore, independently testing internals or values through their interfaces can ease most of the testability problems of the original tests. However, this comes at the cost of tighter coupling between the tests and the production code.
2. 2. 2. Trade-off and contexts.
There’s a trade-off between structure-insensitivity, and other desirable test properties like specificity, composability, readability and writability. There’s no ideal general solution, so we’ll have to “pick our poison” depending on the context.
In a context in which we don’t have enough knowledge yet about the problem to delimit the object’s boundaries well, it’s likely that we’ll do a lot of refactoring as we learn more about the domain. Some of those refactorings may involve refining the interfaces of the new types we introduced by applying the breaking out.
In a context marked by volatility and limited knowledge, it’s preferable to maintain a high degree of structure-insensitivity to avoid increasing the cost of refactoring while preserving other desirable test properties, ensuring that applying new learnings remains inexpensive. That is precisely why we decided not to impose much structure when we started test-driving the behaviour through the entry point.
If after the breaking out, we are still in the same context of volatility and lack of knowledge, it might be wise to defer independently testing the extracted types independently and continue relying on the original tests for a while. In this kind of context, testing them independently might be dangerous because it prematurely couples the tests to interfaces that we may later realize were not sound, leading to more expensive refactorings to refine those internal interfaces.[1]. Keeping the original tests with low specificity, composability, readability and writability will eventually slow us down and produce maintainability problems, but for a while, having a high structure-insensitivity might pay off by allowing cheaper refactoring of internal interfaces.
This trade-off pays off well until it doesn’t 🙂. This happens when the pain of poor specificity, readability, composability and/or writability starts weighing more than the benefits of cheap refactoring due to high structure-insensitivity. This tipping point may happen due to different reasons, for instance:
1. More knowledge and low volatility.
We have learned enough about the problem so that the code is more stable and has some degree of structure. Interfaces and abstractions are more stable, and their refactoring becomes less likely.
2. Too much testability pain.
The behaviour of some internals becomes so complex that it exacerbates the testability problems so much that they weigh more than the benefits of cheap refactoring of interfaces.
2. 2. 3. Consequences of deferring testing “problematic” types independently.
Poor readability and writability.
We might somehow palliate the pain by using explanatory helper methods and test patterns such as test data builder, object mother, etc. Keep in mind that these techniques only alleviate the symptoms; they don’t address the root of the problem. Even so, they are very useful for reducing the pain caused by poor readability and writability during the period in which higher structure-insensitivity is advantageous for us.
Poor specificity.
If this problem starts being especially painful, we may need to start testing independently some problematic internal or value. I think there’s no other technique to reduce this kind of pain. Although, we might get lucky and not get regressions that are difficult to interpret.
Poor composability.
This problem may even make it impossible to defer independently testing a new type that is causing it. As we said before when talking about behavioural composition, we won’t be able to test-drive complex behaviours without breaking them into smaller behaviours. In such cases, we would have no other choice but to start test-driving independently the “problematic” internal or value in order to reduce the size of the increments of behaviour we are tackling. We’ll see that this may or may not involve using test doubles.
2. 2. 4. Conclusions.
To summarize, keep in mind that the strategy of deferring testing the new types independently is beneficial only in a context where we don’t have enough knowledge of the problem because it avoids committing prematurely to any design decision and makes it cheaper to refine the design as we learn.
Having said that, using this strategy in a different context can be dangerous. The more we defer refactoring the tests, the more expensive it will become and the more pain we’ll suffer test-driving new features (accruing and recurring interests of technical debt at play). So don’t wait too long to refactor the tests.
There might be contexts in which we have a more stable design, and/or enough knowledge of the domain. In these contexts, even the initial strategy of test-driving without imposing much structure might make little sense because we have better odds that the design we impose proves successful[2]. We’ll discuss this deeper when we talk about the budding off technique in a future post.
2. 3. Why should we only test “problematic” types independently, and not all types?
We have shown how independently testing the new types produced by a breaking out through their interfaces can ease most of the testability problems of the original tests. However, these gains come at a price: we lose structure-insensitivity because the tests get coupled to the interfaces of the new types.
This trade-off is the reason why we should independently test only the “problematic” types, i.e., the ones that produce painful testability problems. This is a sensible limitation. If we tested independently any internal or value that is not problematic, we’d be trading structure-insensitivity for nothing. This mistake would create unnecessary coupling between our tests and the structure of our code, and we’d be much worse off. The only reason we test any of them independently is to ease testability problems that are becoming too painful[3].
3. Refactoring the tests.
As we said, this is done in two steps:
-
Testing “problematic” internals and values independently.
-
Refactoring the original tests.
Let’s go deeper into each step.
3. 1. Testing “problematic” internals and values independently.
We independently test any internal value that is causing painful testability problems. We don’t need to test all of them at once, instead we can do it incrementally as needed. As we saw, these new tests will ease most of the testability problems of the original tests. Once we have them in place, we can simplify the original composite object’s tests to make them easier to maintain.
3. 2. Refactoring the original tests.
Remember that, after applying a breaking out to improve cohesion, all the extracted collaborator objects are treated as internals. Promoting[4] any of those internals to be a peer is a separate, explicit decision we have to take. This means that there are two options to refactor the original composite object’s tests, each with its own advantages and disadvantages:
- Not promoting any “problematic” internal to be a peer.
- Promoting “problematic” internals to be peers.
3. 2. 1. Not promoting any “problematic” internal to be a peer.
3. 2. 1. 1. How to do it?
If we take this option, what we can do to simplify the original composite object’s tests would be to remove most of the test cases addressing behaviours that are now being independently tested through closer, more appropriate interfaces. We are taking advantage of the improvement in composability that the tests through more appropriate interfaces provide.
Let’s see how doing this improves different testability problems.
3. 2. 1. 2. Consequences.
Writability and readability problems.
The size of the composite object’s tests is reduced, which makes them less unfocused 🚀. In a way, the pain caused by poor writability and readability is still there, but we don’t feel it so much because there are fewer test cases through the interface of the composite object.
Specificity problems.
These problems were already addressed by testing problematic types independently. We’ll still find tests that are checking the same behaviour from different interfaces, only that there are fewer because we have deleted some composite object’s tests. This overlap still causes that a regression can make several tests fail, however, it’s easier to diagnose the origin of the failures: if some composite object’s test cases and some more focused test cases fail, the problem is likely located in an internal or a value, whereas, if only the composite object’s tests fail, the problem is likely located in the composite object.
Composability problems.
Choosing not to promote any internal to be a peer when simplifying the composite object’s tests does not improve composability any further than what testing a problematic internal independently does. However, it forces a way of doing TDD when faced with hard composability problems: when we are not able to test-drive an object because we can’t find a way to decompose its behaviour in small increments, we go one level of abstraction down, test-drive an internal type with a smaller behaviour, and then use that inner behaviour as a stepping stone to test-drive the original behaviour more easily (this is what we would do in the classical style of TDD). Working this way is inside-out in nature, and, as such, is less YAGNI friendly than test-driving outside-in. To palliate this problem, we should be careful to only test-drive the internal behaviour that we need to make test-driving the whole behaviour possible, and no more.
3. 2. 1. 3. Some observations.
Finally, we’d like to add two observations:
- Choosing not to promote any internal to be a peer when simplifying the composite object’s tests does not lower any further the structure-insensitivity. The loss of structure-insensitivity was already caused by independently testing problematic internals through their interfaces.
- If specificity and/or composability problems are very painful, we may be better off promoting the internals causing the pain to be peers. However, if those problems aren’t so painful and we are still worried about structure-insensitivity, not doing it might be tolerable, because, as we’ll see in the next session, promoting them introduces a little more coupling.
3. 2. 2. Promoting some “problematic” internals to be peers.
3. 2. 2. 1. How to do it?
Let’s start by discussing what it takes to promote an internal to be a peer of the composite object:
- Invert the dependency. This may involve refining the interface of the internal and, in the case of statically typed languages, extracting an interface.[5].
- Simulate the peer’s behaviour with test doubles in the composite object’s tests.
- Inject the peer (previously an internal) into the composite object.
3. 2. 2. 2. When should we do it?
In our opinion, we should promote any internal that clearly matches a peer stereotype[6]. They were already dependencies, strategies or notifications from the outset, but we decided to include their behaviour in the scope of our original tests because we weren’t sure about their interfaces. Now that we have learned more, promoting them to peers will greatly improve testability.
In the case of internals that don’t clearly match any peer stereotype, we should promote them to peers only if being a peer provides substantial testability benefits. In this case, we would be treating an actual internal into a peer, which means coupling to an internal detail, so we better be gaining significant improvements in readability, writability, specificity or composability to compensate for the loss in structure-insensitivity. The rich and complex behaviour of these internals is what leads to substantial testability benefits when they are promoted to peers, even though they don’t correspond to any of the object peer stereotypes. We argue that they belong to what Fowler calls “objects with interesting behaviour”[7].
3. 2. 2. 3. Consequences.
Let’s see how choosing this option affects the test properties we have been discussing throughout the post:
Writability and readability.
On one hand, tests of the composite object that use test doubles verify only the composite’s own behavior, making them shorter and more focused. They also document the communication protocols between the composite object and its peers[8].
On the other hand, the more focused tests written through the interfaces of the peers will check only their behaviour and document how they fulfill their roles (contracts).
Specificity.
It is much better with this option. Now, a failure can affect only either the composite object’s tests or a peer’s tests, so it’s straightforward to know where the problem is.
Composability.
It is addressed by simulating the behaviour of the peers (their roles) with test doubles while test-driving the behaviour of the composite object. Afterwards, we test-drive the implementation of the roles to verify that they behave according to their roles.
In the tests of the composite object we describe what we expect of the peer, the contract (or role) between the composite object and its peer, whereas in the tests of the peer we verify that it indeed fulfills that contract.
This is more outside-in and more YAGNI friendly than the approach required in the previous option.
Structure-insensitivity.
Now, both the tests of the peer and the composite object are coupled to the peer’s interface. The tests as a whole see the same set of interfaces as in the previous option, but the number of tests coupled to the peer’s interface increases. Therefore, this option increases the coupling between the tests and the production code. This higher degree of coupling might be attenuated using fakes or using hand-made spies and stubs, but we think this may introduce other maintainability problems on its own[9].
4. Conclusions.
In this post, we addressed the questions we raised in our previous post devoted to the breaking out technique:
Question 1: Should we refactor the tests now or later?
After Applying a Breaking Out refactoring, the original tests still have poor readability, writability, specificity, and composability. Despite these disadvantages, such tests have high structure-insensitivity, meaning they are resilient to internal refactorings. We discussed the trade-off between keeping this structure-insensitivity and improving other properties. Testing the new internal types independently can ease many testability issues, but it also couples the tests to specific interfaces, making their refactoring more costly.
From that trade-off, we derived a key insight: the decision to refactor tests immediately or defer it depends on context. In volatile or poorly understood domains, deferring independent testing of the new types preserves flexibility and reduces refactoring costs, even if it temporarily worsens test quality. As our understanding of the domain grows and the design stabilizes or the testability pains grow, it becomes beneficial to refactor the tests.
Question 2: How do we refactor the tests?
This refactoring is done in two steps: first, we test “problematic” types independently, and then we simplify the original tests. Testing “problematic” types independently improves the readability, writability, specificity, and composability of the tests, though at the cost of greater coupling with the production code. Therefore, we should only test independently those internals or values that cause clear testability pain, thus avoiding introducing coupling for little benefit.
There are two ways to simplify the original composite object’s tests, depending on whether we decide to promote some problematic internals to peers or not. If we decide not to do it, we simplify the composite object’s tests by deleting some test cases; if we decide to do it, we simplify them by introducing test doubles. The first option doesn’t add much improvement over testing “problematic” types independently, but still reduces the degree of pain by having fewer test cases. Promoting “problematic” internals to peers enhances the desirable properties of tests even more, but introduces greater coupling, since the composite object’s tests also become coupled to the new interfaces.
Question 3: How do we decide if we should promote an internal object to be a peer?
We argued that all internals that match peer stereotypes should be promoted to peers to gain testability benefits. Seeing the decision of promoting an internal to a peer as a bet, promoting one that clearly matches a peer stereotype is a bet with good odds. In contrast, promoting a “problematic” internal that doesn’t match any peer stereotype has worse odds, so, to avoid increasing coupling for little or no gain, we need to be very confident that its promotion will provide clear testability benefits before doing it. We discussed what to assess to make a better decision. We also noted that evaluating these odds depends on both experience and the stability of the design.
Final words.
In summary, the key takeaway is that we have many options, and by identifying the trade-offs between different testability properties, we can judge them according to context and the maturity of the design. Balancing cohesion, testability, and flexibility is not a one-time decision but an evolving process.
Thanks for coming to the end of this post. We hope that what we explain here will be useful to you.
The TDD, test doubles and object-oriented design series.
This post is part of a series about TDD, test doubles and object-oriented design:
-
The class is not the unit in the London school style of TDD.
-
“Isolated” test means something very different to different people!.
-
Heuristics to determine unit boundaries: object peer stereotypes, detecting effects and FIRS-ness.
-
Breaking out to improve cohesion (peer detection techniques).
-
Refactoring the tests after a “Breaking Out” (peer detection techniques).
-
Bundling up to reduce coupling and complexity (peer detection techniques).
5. Acknowledgements.
Finally, I’d also like to thank Ali Soheil for the photo.
6. References.
-
Growing Object Oriented Software, Guided by Tests, Steve Freeman and Nat Pryce.
-
Thinking in Bets: Making Smarter Decisions When You Don’t Have All the Facts, Anne Duke
-
Test-Driven Design Using Mocks And Tests To Design Role-Based Objects , Isaiah Perumalla.
-
Mock roles, not objects, Steve Freeman, Nat Pryce, Tim Mackinnon and Joe Walnes.
-
Mock Roles Not Object States talk, Steve Freeman and Nat Pryce.
-
Test Desiderata 2/12 Tests Should be Structure-Insensitive, Kent Beck.
-
Object Collaboration Stereotypes, Steve Freeman and Nat Pryce.
-
The class is not the unit in the London school style of TDD, Manuel Rivero
-
“Isolated” test means something very different to different people!, Manuel Rivero
-
Heuristics to determine unit boundaries: object peer stereotypes, detecting effects and FIRS-ness, Manuel Rivero
-
Breaking out to improve cohesion (peer detection techniques), Manuel Rivero
7. Notes.
[1] An extreme case of poor structure-insensitivity happens when we fall in the dangerous class-as-unit trap. Never go there, it’s a scenario full of pain.
Read The class is not the unit in the London school style of TDD, if you are using the London school style of TDD (or mockist TDD).
[2] Design decisions are always a bet against the future evolution of a system.
When we are assessing the quality of a decision, it’s important that we don’t take into account its result, which is a very common cognitive bias called “fielding outcomes” that impairs our learning loops.
So, we should assess a decision thinking if it had good odds to be successful given what we knew at the moment we took it, independently of its result.
You can read more about improving decision making in an uncertain world in Anne Duke’s wonderful Thinking in Bets: Making Smarter Decisions When You Don’t Have All the Facts book.
This interview, Thinking in Bets for Engineers, is very interesting as well.
[3] We consider that thinking about testability benefits to decide whether to independently test new types introduced through refactoring or not is useful in the context of a breaking out. There could be other valid reasons to write those new tests. You can read the following two posts to go deeper into this topic:
- Additional Testing After Refactoring, Kent Beck
- Revise Tests While Refactoring? It Depends, Bill Wake
- The Impact of Refactoring on Tests, Bill Wake
[4] “Promoting” is a refactoring that makes the role of an internal of an object seen by the rest of the system and the object’s tests. This means that it is treated as a peer of the object. The inverse refactoring of promoting is materializing which “demotes” a peer of an object to be an internal.
[5] We’d like to note some things about this:
- In statically typed languages.
We need to extract an interface because we have two implementations: one in the test context and another one in the production context. We shouldn’t simulate a concrete class with test doubles, even if the tool we use allows it. Simulating a concrete class leaves the relationship between the objects implicit. Read Test Smell: Mocking concrete classes for more details.
The meaning of “extracting an interface” depends on whether the language has an interface construct or not: for instance, we would extract an interface in Java or C#, but extract a class whose methods are all pure virtual functions in C++ (at least in the version I used to use).
- In dynamically typed languages.
We don’t need to extract an interface to invert the dependency.
In both cases we should work to avoid the peer’s API from leaking any implementation detail.
[6] For the GOOS authors the communication patterns between objects are more important than the class structure, (see section Communication over Classification in chapter 7: Achieving Object-Oriented Design).
[7] We commented how using test doubles in an object’s tests to simulate a collaborator that clearly matches a peer stereotype provides substantial testability benefits in our previous post Heuristics to determine unit boundaries: object peer stereotypes, detecting effects and FIRS-ness.
If the behaviour of the object is very simple (cyclomatic complexity = 1), we may get by with a broad integration test.
[8] It appears in the section Classical and Mockist Testing of his post Mocks Aren’t Stubs:
“[…] always use a mock for any object with interesting behavior”.