Mutantes relevantes
Published by Manuel Rivero on 25/04/2025
Este post es una traducción al español con algunas mejoras y actualizaciones del post original en inglés Relevant mutants.
1. Introducción.
Usar mutation testing nos da información sobre la capacidad de detección de errores de nuestros tests, es decir, sobre si las aserciones contenidas en dichos tests son lo suficientemente buenas como para detectar regresiones.
La técnica de mutation testing se basa en inyectar intencionalmente una regresión en una copia del código, “el mutante”, para después ejecutar los tests contra dicho mutante y verificar si alguno de los tests falla:
-
Si falla algún test, todo va bien, “los tests han matado al mutante”. Esto significa que nuestros tests nos protegen de ese tipo de regresión.
-
Si no falla ningún test, “el mutante sobrevive”, y esto podría no ser bueno. Que un mutante sobreviva quiere decir que nuestros tests no nos protegen de que ocurra esa regresión. Es posible que hayamos encontrado algo que debemos mejorar en nuestros tests.
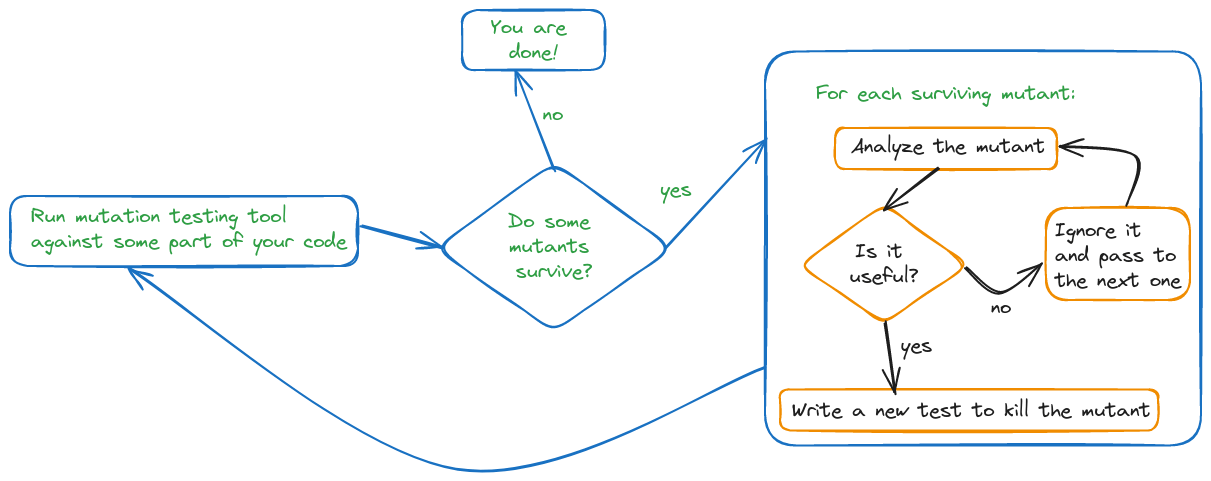
Sin embargo, cuando aplicamos mutation testing no todos los mutantes supervivientes son una señal de debilidades en los tests, este fenómeno es aún más significativo en código legacy.
Por un lado, es posible que algunos de los supervivientes estén relacionados con la existencia de código muerto, mientras que otros podrían indicar código que es innecesario para producir el comportamiento esperado y, por lo tanto, podría simplificarse[1].
Es por esto, que debemos analizar cada mutante superviviente para determinar si es relevante o no, y sólo en caso de serlo, escribir nuevos tests para eliminarlo.
Veámoslo con un ejemplo.
2. Análisis de los mutantes supervivientes en la kata Crazy Portfolio.
La kata Crazy Portfolio es una kata para practicar con código heredado que publicamos no hace mucho. Esta kata es compleja porque el código de la clase Portfolio además de tener muchas responsabilidades y una lógica condicional compleja, utiliza fechas y zonas horarias y produce side-effects. Por si esto fuera poco existen muchas particiones con sus correspondientes fronteras y algunas invariantes de clase implícitas[2].
En el código que utilizaremos en este ejemplo ya habíamos escrito tests de caracterización que lograban la máxima cobertura de rama posible. La cobertura de rama no puede ser del 100% porque hay una rama inalcanzable en el código de producción, y porque las costuras que introdujimos usando Extract and Override Call para romper dependencias y poder testear el código, por supuesto, no se ejecutan en los tests.
Dependiendo del refactoring que deseemos hacer, podría ser que una cobertura de rama alta no fuera suficiente para comenzar a refactorizar con confianza. Por este motivo decidimos aplicar mutation testing usando Stryker.
El resultado de aplicar mutation testing fue que 36 de 160 mutantes sobrevivieron, con lo que, parecía que tendríamos mucho trabajo de mejora en nuestros tests agregando nuevos casos de test para eliminar todos esos mutantes, y quizás algunos de ellos no serían fáciles de eliminar.
Si analizamos los mutantes supervivientes, veremos que realmente no había tantos mutantes que eliminar.
Los mutantes supervivientes se pueden clasificar en las siguientes categorías:
- Mutantes en código muerto.
- Mutantes en costuras.
- Mutantes en código que no se utiliza desde los tests debido a las costuras.
- Mutantes en código superfluo que no indican debilidades en los tests.
- Mutantes que sí indican debilidades en los tests.
Analicemos las distintas categorías una por una.
2. 1. Mutantes en código muerto.
Esta categoría incluye todas las mutaciones contenidas en la rama no accesible que está en la línea 60, que ya habíamos identificado cuando escribimos los tests de caracterización.

Estos mutantes supervivientes son obviamente irrelevantes.
2. 2. Mutantes en costuras.
Todos los mutantes supervivientes dentro de las costuras que introdujimos al romper dependencias para poder testear el código, como por ejemplo, el método createDate que se muestra en el siguiente fragmento del informe de Stryker, no son relevantes porque el código incluido en las costuras no se ejecuta en los tests.

Lo mismo sucede con los mutantes que sobreviven dentro de las otras costuras: los métodos protegidos: formatDate, getAssetLines, displayMessage y getNow.
2. 3. Mutantes en código que no se utiliza desde los tests debido a las costuras.
En este grupo encontramos la mutación que sobrevive dentro del constructor de la clase Portfolio,

Como introdujimos una costura para poder obtener los activos del portafolio sin tener que leer el archivo en los tests unitarios, getAssetLines, el campo portfolioCsvPath no se utiliza para nada, por lo tanto, el mutante superviviente mostrado en la figura anterior no es una mutación relevante.
Sobre las categorías que hemos analizado hasta ahora.
Los mutantes supervivientes en las tres categorías que hemos visto hasta ahora se pueden ignorar de forma rápida y segura porque no proporcionan ninguna pista sobre cómo mejorar los tests o el código de producción. Se trata de mutantes supervivientes código no ejercitado por los tests.
Las cosas no son tan sencillas con el resto de mutantes supervivientes, que caen en las dos categorías que nos falta por analizar.
Tendremos que examinarlos uno por uno para ver si realmente indican debilidades en nuestros tests, o si apuntan a código de producción superfluo que podría simplificarse.
Veamos las dos categorías restantes.
2. 4. Mutantes en código superfluo que no indican debilidades en los tests.
Analicemos los ejemplos más interesantes:
- Caso 1: Mutaciones que sobreviven en la línea 29.
Observen esta mutación que cambia un operador de división por un operador de producto:

o esta otra mutación que cambia un operador de producto por un operador de división:

Hay varias mutaciones similares más en la misma línea.
Estas mutaciones que reemplazan el operador de división por el operador de producto parecen muy confusas y, al principio, pueden resultar incluso desconcertantes. ¿Por qué sobreviven?
Para comprenderlo, debemos analizar con más detalle la condición que se está mutando y su significado.
Al hacerlo, vemos que lo único relevante para que la condición Math.floor(asset.getDate().getTime() - now.getTime() / (1000 * 60 * 60 * 24)) < 0 sea verdadera o falsa es el signo de la diferencia entre los dos tiempos en milisegundos: asset.getDate().getTime() - now.getTime().
El resto de la expresión, (1000 * 60 * 60 * 24), es simplemente un número positivo (se trata un factor de conversión para pasar de milisegundos a días) que no cambiará el signo de dicha diferencia de tiempo, y, por lo tanto, no cambiará la evaluación de la expresión booleana completa, Math.floor(la_diferencia_de_tiempos / el_numero_positivo) < 0.
Esto quiere decir que todos esos mutantes que cambian los operadores / por * no están señalando ningún tipo de debilidad en nuestros tests. Lo que realmente indican es la existencia de código de producción innecesario, en este caso la conversión de milisegundos a días, que podríamos simplificar[3], quedando la siguiente condición: Math.floor(asset.getDate().getTime() - now.getTime()) < 0.
Esta simplificación (que sólo haríamos una vez tuviésemos tests más fuertes que ya eliminen todos los mutantes relevantes) sería suficiente para eliminar todos los mutantes relacionados con código superfluo en la línea 29.
- Case 2. Mutaciones que sobreviven en la línea 27.

Esta mutación superviviente hace que nunca se creen objetos de la clase PricelessValue (la condición es sustituida por un false), y aún así los tests siguen pasando. ¿ Cómo puede ocurrir esto?
Que estos mutantes sobrevivan quiere decir que, o bien, tenemos alguna debilidad en los tests, o bien, que la clase PricelessValue no es necesaria para el comportamiento que los tests están protegiendo. Para entender qué opción es la correcta debemos preguntarnos cómo es que estas mutaciones han sobrevivido.
Si miramos con atención el código, nos daremos cuenta de que estas mutaciones sobreviven porque la clase derivada PricelessValue no se utiliza en absoluto en el código.
En el código de producción sólo se está utilizando el getter de la clase base de la jerarquía, MeasurableValue, y por lo tanto, toda la jerarquía de herencia es superflua. La causa detrás de este problema es la feature envy contra la clase Asset que existe en el código actual, es más Asset es una data class.
De nuevo, estos mutantes no son relevantes para mejorar nuestros tests y no tenemos que perder el tiempo intentando matarlos ahora.
Cuando ya tengamos mejores tests que eliminen todas las mutaciones relevantes, podremos refactorizar el código para eliminar la feature envy rampante contra la clase Asset, y decidir si es necesario mantener o no la jerarquía MeasurableValue. Por tanto, una buena asignación de responsabilidades eliminaría las mutaciones de la línea 27 que hemos comentado.
5. Mutantes que sí indican debilidades en los tests.
Sólo uno de los mutantes de la línea 29 es relevante para mejorar nuestros tests, el que cambia el operador < por el operador <=:

La supervivencia de este mutante nos está indicando que nuestros tests no están ejercitando correctamente los valores alrededor de una frontera entre diferentes comportamientos o particiones.
Hay otros mutantes supervivientes similares al anterior que también indican problemas al testear valores alrededor de una frontera, por ejemplo los de las líneas 32 y 46 que se presentan a continuación:


Otro ejemplo de un mutante superviviente que puede indicar una debilidad en nuestros tests es el de la línea 22 que se muestra a continuación:
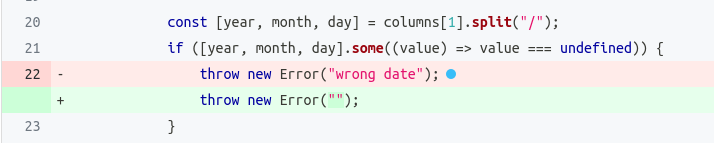
Si examinamos los test, veremos que lo que estamos comprobando es si se lanza una excepción cuando la fecha tiene un formato incorrecto, pero no estamos comprobando el mensaje de la excepción. En este caso, para eliminar este mutante habría que hacer que los tests se acoplen al texto concreto ”wrong date”.
En nuestra opinión, el mensaje concreto de error es un detalle volátil y acoplar los tests a él sería una especificación excesiva que aumentaría innecesariamente la fragilidad de los tests. Para evitarlo decidimos ignorar dicho mutante.
Conclusiones.
Hemos mostrado un ejemplo de cómo no todos los mutantes supervivientes indican debilidades en nuestros tests. De los 36 mutantes supervivientes originales, solo 13 acabaron siendo relevantes para mejorar nuestros tests[4] (optamos por ignorar el mutante superviviente relacionado con el mensaje de error). En este caso, los 13 mutantes relevantes están relacionados con fronteras entre comportamientos que los tests no están chequeando correctamente.
Como los mutantes supervivientes, a veces, no son fáciles de eliminar[5], está muy bien saber identificar aquellos que no son relevantes para mejorar los tests.
Matar 13 mutantes es una tarea mucho menos abrumadora que matar a 36, pero tuvimos que invertir tiempo en analizar los 36 mutantes para ver si eran relevantes o no. Lo bueno es que la mayoría de los mutantes descartados e irrelevantes fueron fáciles de identificar: los relacionados con la existencia de código muerto[6] y los relacionados con la introducción de costuras.
También discutimos otra categoría de mutantes supervivientes que, si bien no señalan la necesidad de mejorar los tests, son una señal de código que podría ser innecesario para lograr el comportamiento deseado. Esta información puede ser muy interesante para guiar refactorizaciones posteriores, una vez hayamos mejorado los tests eliminando los mutantes relevantes.
Espero que este ejemplo detallado les pueda resultar útil al analizar los resultados de aplicar mutation testing.
Agradecimientos.
Me gustaría agradecer a Fran Reyes y Rubén Díaz por revisar borradores de este post.
También agradecemos a los desarrolladores de Audiense por haber sido los beta testers de la kata Crazy Portfolio como parte de las sesiones de práctica deliberada que llevamos haciendo desde hace unos años. Siempre es un placer trabajar con ustedes.
Por último, también me gustaría darle las gracias a Carlos Machado por la foto del post.
Notas.
[1] Estos dos tipos de falso positivo (mutantes irrelevantes) están directamente relacionados con los code smells Dead Code y Speculative Generality que William Wake clasifica bajo la categoría Unnecessary Complexity. Ver nuestro post De taxonomías y catálogos de code smells.
[2] Solíamos usar una versión simplificada de esta kata en nuestro curso Cambiando Legacy Code, pero al final decidimos cambiarla por otra kata un poco más sencilla.
[3] Ya hablamos de mutantes supervivientes que señalan código redundante en un post anterior: Mutando para simplificar.
[4] Los 13 mutantes supervivientes relevantes se encuentran en las líneas 29 (1), 32 (2), 46 (2), 70 (1), 71 (2), 76 (1), 77 (2) y 83 (2).
Los mutantes supervivientes en las líneas 32, 46, 77 y 83 señalan fronteras entre comportamientos que los tests están ignorando por completo (por ese motivo puede sobrevivir una mutación que elimina completamente la condición), mientras que los mutantes supervivientes en las líneas 29, 70 y 76 indican fronteras entre comportamientos que los tests sólo están probando parcialmente.
[5] Probar bien las fronteras entre diferentes comportamientos y, por lo tanto, eliminar mutantes relacionados con ellas se vuelve mucho más fácil si se conocen los conceptos de on-point y off-point de una frontera. Este conocimiento proporciona un método sistemático para eliminar este tipo de mutantes. En el material actualizado de nuestra formación de TDD enseñamos a analizar y testear correctamente valores de frontera.
[6] Nuestra recomendación es que, antes de usar una herramienta de mutation testing, utilicen una herramienta de cobertura para detectar código no cubierto por los tests y código muerto, ya que, los resultados de las herramientas de cobertura son mucho más fáciles de analizar que los resultados de las herramientas de mutation testing.